1. 实验环境
- OS: Ubuntu Kylin 15.04
- IDE: JetBrains Pycharm 4.5.4
- Programming Language: Python 2.7
2. 实验方案设计
2.1 程序结构
- token.py: 词法单元
- lexer.py: 词法分析器
- parser.py: 语法分析器
parser将读入的源代码传递给lexer进行词法分析, lexer每次识别一个在token.py中定义的TOKEN,并将其传递给parser进行下一步分析。
2.2 源代码读入
待处理的源代码可以从键盘读入也可以从文件读入。对于文件读入方式,parser只需要把打开后的文件对象传递给lexer即可。而对于键盘读入,为了将两种方式进行统一,采取的方式是先将键入的源代码全部读取完毕,然后将读入的字符串转换为file-like object。file-like object的读取方式与真实的文件对象一致,从而完成了两种输入方式的统一。
运行时,在可执行程序后面加入文件路径参数则表示从文件读入,不加参数则表示从键盘读入。
2.3 词法单元识别
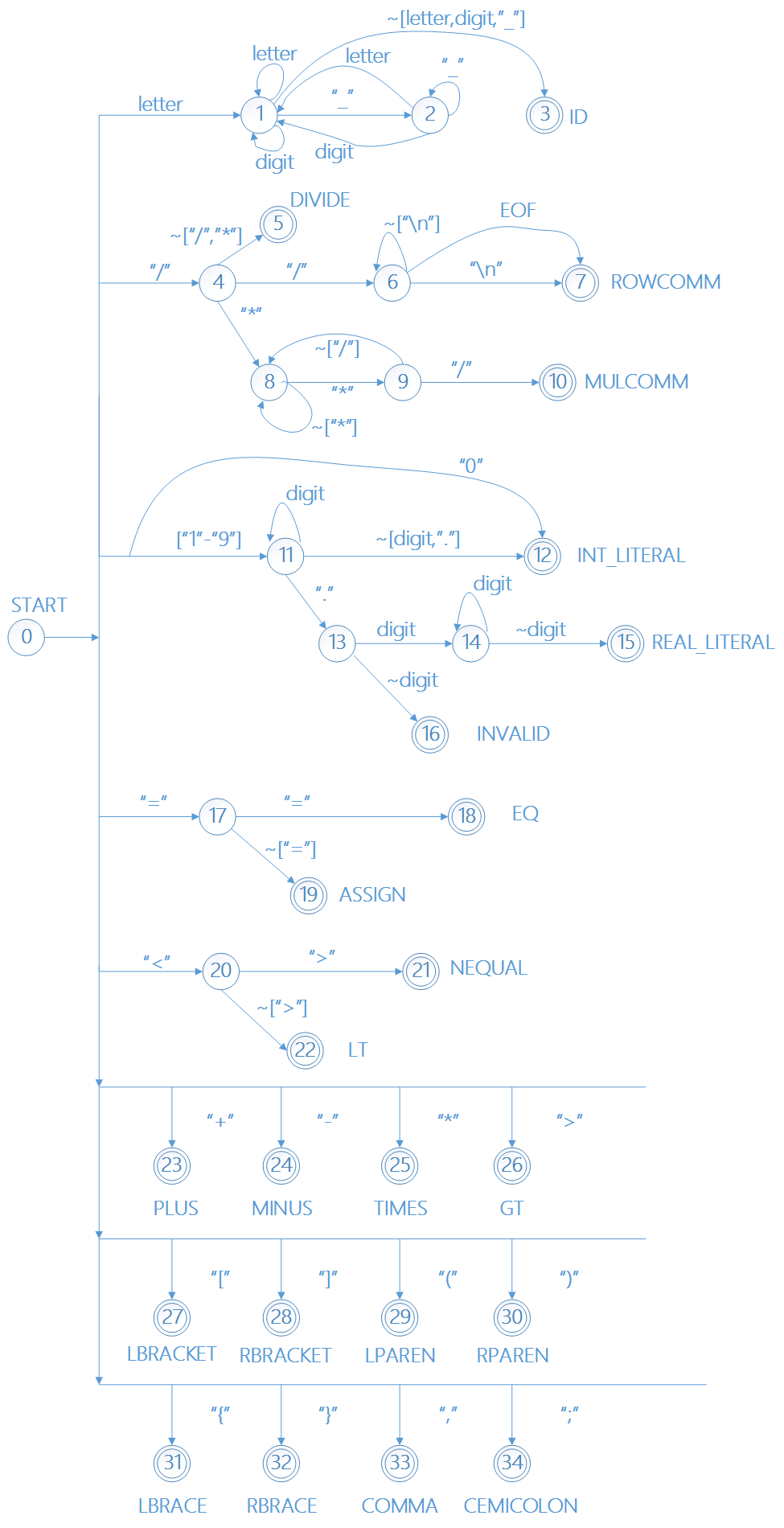
首先,需要根据CMM词法特性构造出其对应的DFA,然后再根据DFA构造其状态转换表,再根据状态转换表构建分析程序。DFA中,每个结束状态都表示成功识别一个词法单元。当成功识别一个词法单元之后,重新回到DFA中的开始状态,再次进行识别,直到EOF为止。
理论上,需要维护一个状态转换表,其结构为一维数组。数组角标对应于DFA中的状态编号,其值为一个dict,dict中存储了状态转换键值对。其中,key对应于DFA中的转移字符,value对应于转换后的状态。终止状态对应于其识别到的TOKEN。
然而,由于构建的DFA比较简单,lexer处理程序中并没有机械性地根据状态转换表进行识别,而是根据DFA直接采用传统的if-else结构进行词法分析。(其实是因为刚开始没有想到用状态转换表,写完了才意识到;而且转换表的状态太多了,还不如就用if-else判断方便)
2.4 字符读取
lexer处理程序会将源代码中的字符逐个读取,并逐个识别。当读到一个“脏字符”时,标志者当前的TOKEN识别结束,重新回到DFA的开始状态。而重新开始识别时,需要再次使用到之前读取的“脏字符”。因此,需要维护一个输入缓冲区。
缓冲区其实是一个堆栈,FILO。当读到“脏字符”时,我们将其放入缓冲区,并结束当前的识别,返回识别到的TOKEN。接着,从DFA的开始状态重新开始识别。再次读取字符时,需要先判断缓冲区是否为空,若缓冲区还有字符,则将缓冲区中的字符依次弹栈,直到清空为止。待缓冲区为空后,再从输入源读取字符。
例如,假设输入字符串为2.3564bcd,当读完2.3564时,我们判定它为real类型的TOKEN,并且我们期望在其之后的字符都是数字。接着往下读取,字符b被读入,它不是数字,因此不能作为之前识别的real TOKEN的一部分。所以,我们将其放入缓冲区,结束当前的识别,返回的词法单元为<REAL:"2.3564">。然后,我们回到DFA的开始状态,重新开始识别。由于缓冲区中还有字符,因而优先选择从缓冲区读取。所以,字符b被再次读取。最后,下一个被识别的词法单元为<ID:"bcd">。
2.5 错误处理
当遇到非法字符时,需要进行错误处理。本程序中,采用打印错误信息并立即终止程序的方式。打印的错误信息包含非法字符所在行、列,以及错误行的所有内容。比如,遇到0..04545时,错误信息为
Invalid token at row 5, column 9:
int a=0..4545;
^
因此,需要使用几个变量记录当前的信息。line记录当前行号,read记录当前行已经读取过的所有字符。在读到非法字符时,line确定非法字符所在行,read的大小确定非法字符所在列。继续读完当前行未读完的部分,并将其存入read中,即可打印当前行。
当读取一个字符时,不论是从缓冲区还是从源文件,都应该将其加入read;当将“脏字符”放入缓冲区时,同时也应该去除read中读到的脏字符;当遇到换行符时,line递增,并将read清空。
以上方法会遇到一个问题,如果读到换行符并进行递增和清空等换行操作后,发现换行符是“脏字符”,此时需要把换行符放入缓冲区并回到上一行。要是非法字符刚好出现在上一行的末尾,如ab2c_中的_,则需要d打印上一行的所有字符并报错。但是上一行记录的所有字符已经在进行换行操作时被清空,因此我们需要再使用一个变量pre_read来记录换行时上一行的所有字符。
整个字符读取代码如下
def _getch(self):
"""
get char from buffer or input
:return:
"""
if len(self.buf) == 0:
c = self.input.read(1)
if len(c) == 0:
return None
else:
c = self.buf.pop()
if c == '\n': # record current state and prepare for a new line
self.line += 1
self.pre_read = self.read
self.read = []
else:
self.read.append(c)
return c
def _ungetc(self, c):
"""
put a char that was read to buffer
:param c: the char to unget
:return:
"""
self.buf.append(c)
if c == '\n':
# if unget '\n', recover to the previous state which has been recorded
self.line -= 1
self.read = self.pre_read
self.pre_read = []
else:
self.read.pop()
3. 测试
3.1 arithmetic
$ cat test/lexer/arithmetic.t
// This is a test for arithmetic
a+b; a- b; a*b; a / b;
int b=0.00134446
int a=0..4545 // invalid
$ ./parser.py test/lexer/arithmetic.t
2: <ID: 'a'>
2: <PLUS: '+'>
2: <ID: 'b'>
2: <SEMICOLON: ';'>
2: <ID: 'a'>
2: <MINUS: '-'>
2: <ID: 'b'>
2: <SEMICOLON: ';'>
2: <ID: 'a'>
2: <TIMES: '*'>
2: <ID: 'b'>
2: <SEMICOLON: ';'>
2: <ID: 'a'>
2: <DIVIDE: '/'>
2: <ID: 'b'>
2: <SEMICOLON: ';'>
4: <RESERVE: 'int'>
4: <ID: 'b'>
4: <ASSIGN: '='>
4: <REAL_LITERAL: '0.00134446'>
5: <RESERVE: 'int'>
5: <ID: 'a'>
5: <ASSIGN: '='>
Invalid token at row 5, column 9:
int a=0..4545 // invalid
^
3.2 comment
$ cat test/lexer/comment2.t
/**
* This is a test for multiple line comments
*/
int i/*~ /*Ha*ha/* ~*/=0;
/*
Below is a nest comment, which is invalid.
But at lexical analysis state, it's valid,
which can be recognized as "<ID: 'ccc'> <TIMES: '*'> <DIVIDE: '/'>"
*/
/*aaa/*bbb*/ccc*/
$ ./parser.py test/lexer/comment2.t
4: <RESERVE: 'int'>
4: <ID: 'i'>
4: <ASSIGN: '='>
4: <INT_LITERAL: '0'>
4: <SEMICOLON: ';'>
12: <ID: 'ccc'>
12: <TIMES: '*'>
12: <DIVIDE: '/'>
3.3 comparison
$ cat test/lexer/comparison.t
// This is a test for comparison
a>b;a<b;a<>b;a==b;
$ ./parser.py test/lexer/comparison.t
2: <ID: 'a'>
2: <GT: '>'>
2: <ID: 'b'>
2: <SEMICOLON: ';'>
2: <ID: 'a'>
2: <LT: '<'>
2: <ID: 'b'>
2: <SEMICOLON: ';'>
2: <ID: 'a'>
2: <NEQUAL: '<>'>
2: <ID: 'b'>
2: <SEMICOLON: ';'>
2: <ID: 'a'>
2: <EQUAL: '=='>
2: <ID: 'b'>
2: <SEMICOLON: ';'>
3.4 identifier
$ cat test/lexer/identifier.t
//This is a test for identifier
a2b_c // valid
a2b_ // invalid
$ ./parser.py test/lexer/identifier.t
2: <ID: 'a2b_c'>
Invalid token at row 3, column 4:
a2b_ // invalid
^
3.5 reserved
$ cat test/lexer/reserved.t
// This is a test for reserved tokens
int arr[5];
bool p=1;
real a=0.22325;
if(p>0){ write(p)}else{read(p)}
$ ./parser.py test/lexer/reserved.t
2: <RESERVE: 'int'>
2: <ID: 'arr'>
2: <LBRACKET: '['>
2: <INT_LITERAL: '5'>
2: <RBRACKET: ']'>
2: <SEMICOLON: ';'>
3: <RESERVE: 'bool'>
3: <ID: 'p'>
3: <ASSIGN: '='>
3: <INT_LITERAL: '1'>
3: <SEMICOLON: ';'>
4: <RESERVE: 'real'>
4: <ID: 'a'>
4: <ASSIGN: '='>
4: <REAL_LITERAL: '0.22325'>
4: <SEMICOLON: ';'>
5: <RESERVE: 'if'>
5: <LPAREN: '('>
5: <ID: 'p'>
5: <GT: '>'>
5: <INT_LITERAL: '0'>
5: <RPAREN: ')'>
5: <LBRACE: '{'>
5: <RESERVE: 'write'>
5: <LPAREN: '('>
5: <ID: 'p'>
5: <RPAREN: ')'>
5: <RBRACE: '}'>
5: <RESERVE: 'else'>
5: <LBRACE: '{'>
5: <RESERVE: 'read'>
5: <LPAREN: '('>
5: <ID: 'p'>
5: <RPAREN: ')'>
5: <RBRACE: '}'>
附录1:CMM词法对应表
| Token | lexeme |
|---|---|
| IF | "if" |
| ELSE | "else" |
| WHILE | "while" |
| READ | "read" |
| WRITE | "write" |
| INT | "int" |
| REAL | "real" |
| BOOL | "bool" |
| TRUE | "true" |
| FALSE | "false" |
| PLUS | "+" |
| MINUS | "-" |
| TIMES | "*" |
| DIVIDE | "/" |
| ASSIGN | "=" |
| LT | "<" |
| GT | ">" |
| EQUAL | "==" |
| NEQUAL | "<>" |
| LPAREN | "(" |
| RPAREN | ")" |
| LBRACE | "{" |
| RBRACE | "}" |
| LBRACKET | "[" |
| RBRACKET | "]" |
| ROWCOMM | "//" |
| LEFTCOMM | "/*" |
| RIGHTCOMM | "*/" |
| COMMA | "," |
| SEMICOLON | ";" |
| LETTER | ["a"-"z"]|["A"-"Z"] |
| DIGIT | ["0"-"9"] |
| ID | <LETTER>|((<LETTER> | <DIGIT> | "_") * ( <LETTER> | <DIGIT> ))? |
| INT_LITERAL | ["1"-"9"] (<DIGIT>)* | "0" |
| REAL_LITERAL | <INT_LITERAL>("."(<INT_LITERAL>)+)? |