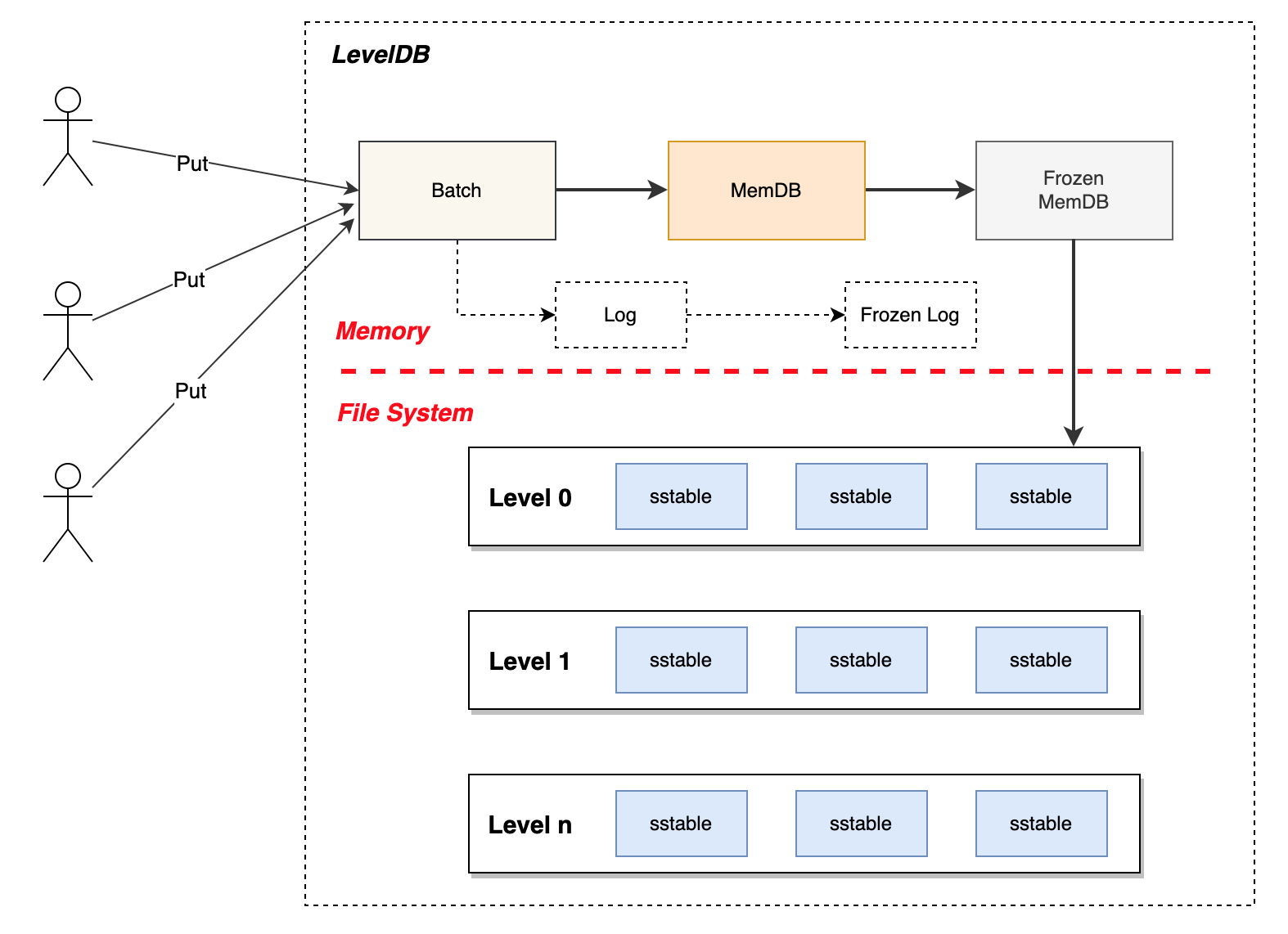
数据在写入 LevelDB 时,并不是立即写入磁盘,而是会先写入内存中,当内存中的数据达到一定数量时,才会写入磁盘。这些内存中的数据统一由 MemDB 来维护,包括数据写入与查询。本文将以 GoLevelDB 源码为例,介绍 MemDB 组件。
整个LevelDB会在内存中维护三种数据,包括Batch、MemDB、FrozenMemDB:
- Batch 包含一条或多条用户待写入的数据
- MemDB 在内存中临时存储写入的数据
- FrozenMemDB 一种只读的MemDB,当 MemDB 数据量达到上限时,切换为 FrozenMemDB
下面将分别介绍 Batch和MemDB。
Batch
有两种方式可以往LevelDB中写入数据,一种是单次写入一条(Put)或者单次写入多条(Write),不论是一条还是多条,在内部都是以Batch的形式组织。另外,并发地多次写入也可以被合并成一个Batch。
func (db *DB) Put(key, value []byte, wo *opt.WriteOptions) error
func (db *DB) Write(batch *Batch, wo *opt.WriteOptions) error
Batch 主要存储了2个数据项,分别是data、index、internalLen:
- data 存储
keyvalue数据 - index 存储索引,即记录每个
key、value在data中的位置。len(index)等于key的数量
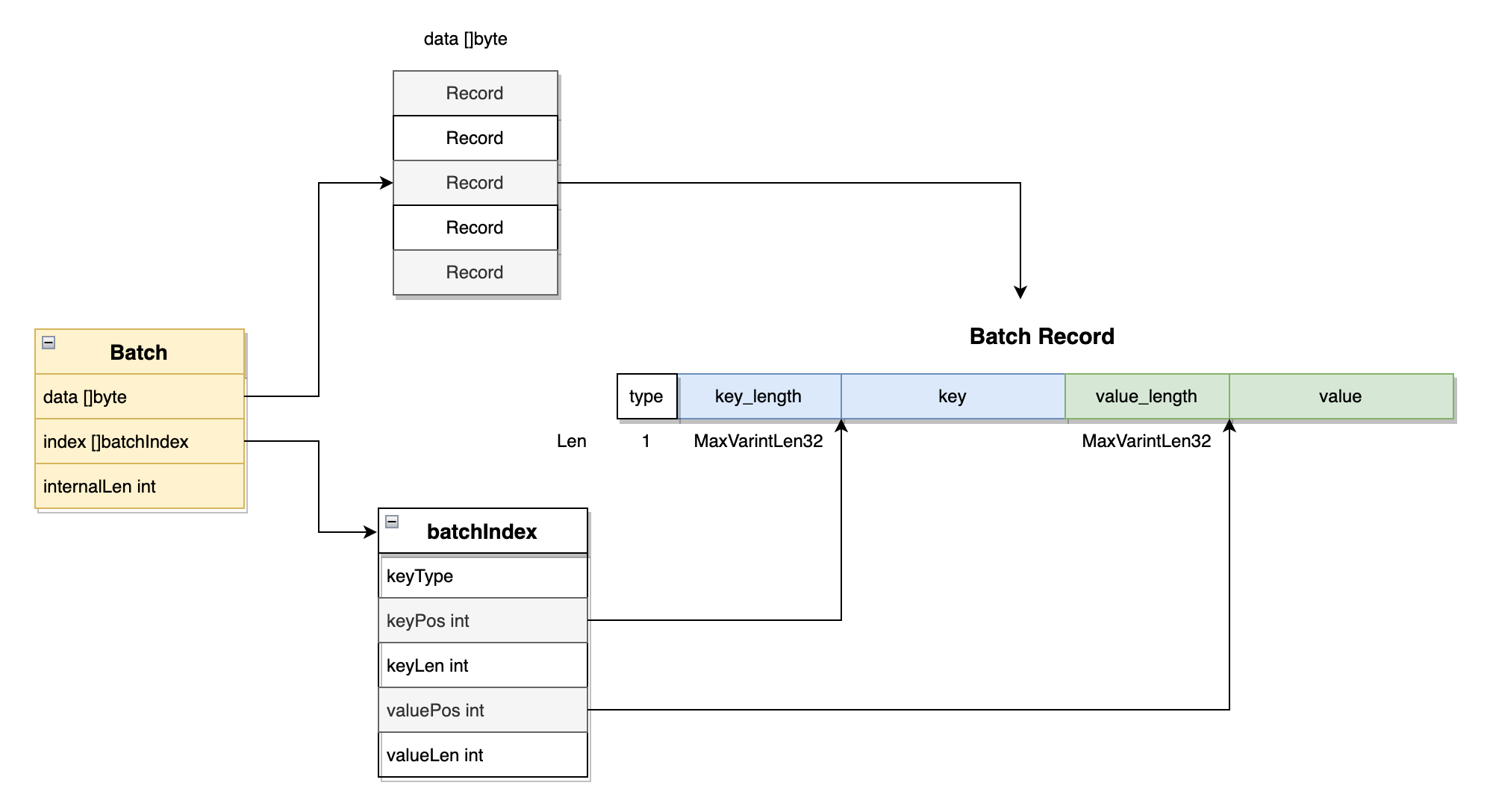
Batch Record
有没有发现多条记录都一起存储在data这个一维数组中,那么怎么判断一条记录的起止区间呢?可以看看上图的Batch Record结构,每条记录中都存储了key_length和value_length。
- type 用1个字节区分
Val和Del,也就是写入和删除 - key_length 用
binary.MaxVarintLen32(5个字节)存储key的长度(最大232字节) - value_length用
binary.MaxVarintLen32(5个字节)存储value的长度(最大232字节);如果type是删除的话,那么就没有value_length和value。
Index
每往Batch中写一条记录时,就会往index这个数组中写入一条索引信息,包括每条记录在data中的位置以及key、value的长度。那么当我们想知道Batch中有多少条数据时,就可以很方便地直接返回len(index)。此外,在遍历Batch时,也可以直接遍历index,通过其记录的keyPos、valuePos来读取数据。
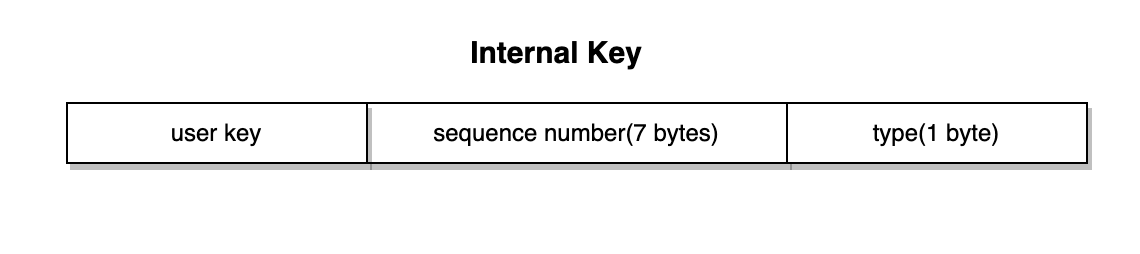
Internal Key
数据从Batch进入到MemDB后,其key就会被转换成internal key,其结构如下图。其实就是在原有的key后面加了8个字节的额外信息,包括7个字节的sequence number和1个字节的type(添加、删除)。sequence number是一个自增的ID,代表了数据的版本号,在本文中暂时用不到。
MemDB
Batch中的数据会写入到MemDB中,MemDB 的默认最大容量是 4MB,当容量达到4MB时,会将其修改为只读状态,记为FrozenMemDB,并重新初始化一个新的MemDB。新的数据会写到新的MemDB中,而FrozenMemDB中的数据会在后台任务中被持久化到文件系统中。如果在FrozenMemDB完成持久化前,新的MemDB也达到了容量上限,那么新的写入请求会被阻塞住,直到FrozenMemDB完成持久化。也就是说,同一时刻,最多只可能有1个MemDB和1个FrozenMemDB存在。
SkipList
MemDB的结构其实是一个 SkipList,这是为了方便查询内存中的数据。数据从Batch中写入MemDB的过程也就是构建SkipList的过程。跳表长这样:
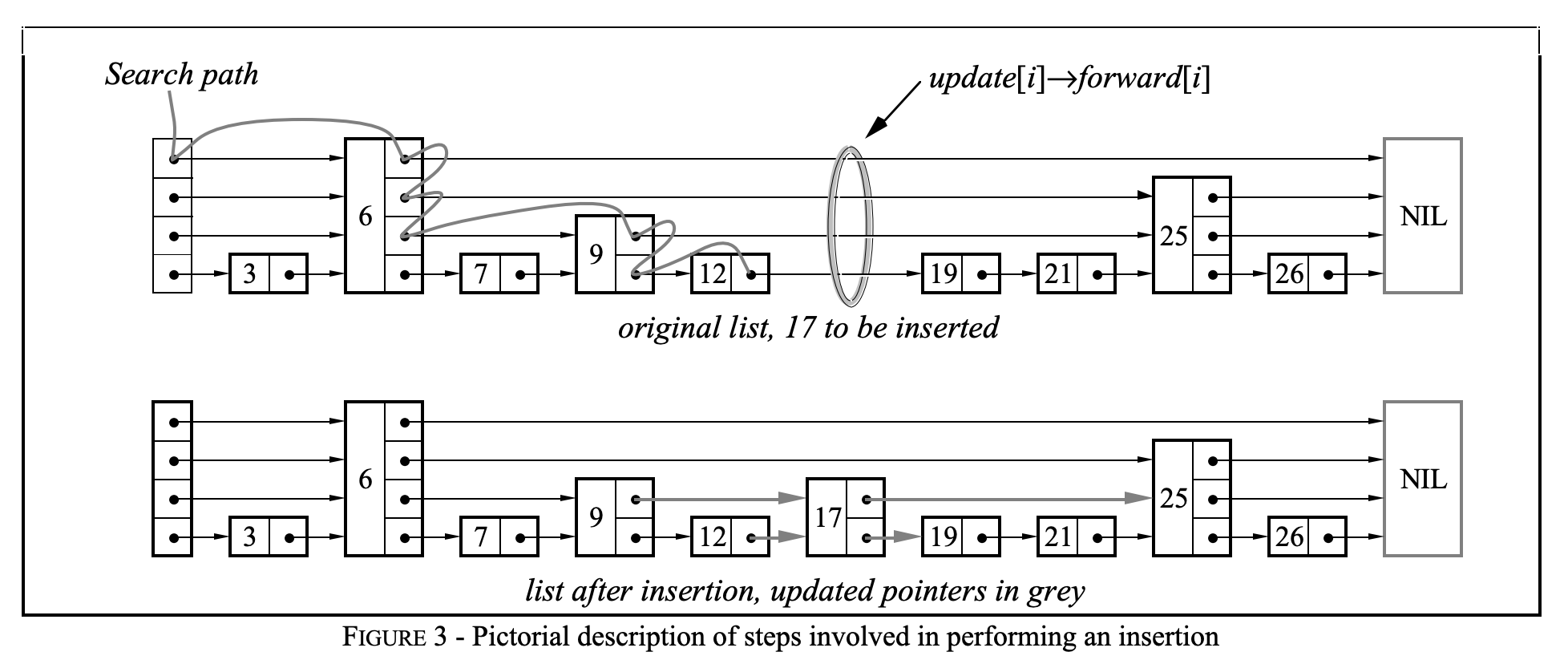
其实就是有很多个节点,每个节点高度不同,每个节点都记录了它在各个高度的下一个节点的指针,每一层都是一个有序链表。越高层的数据量越少,越底层的数据量越大,最底层的链表包含了所有数据。检索的时候从高层往低层移动,相当于二分查找。
该怎么表示 SkipList 呢?最简单的方式是抽象出一个Node的struct,其中存放相关指针和key value数据。但是 GoLevelDB 并没有这么实现,而是把数据和节点分开,并且巧妙地把所有数据/节点都分别存储在了一个一维数组中。
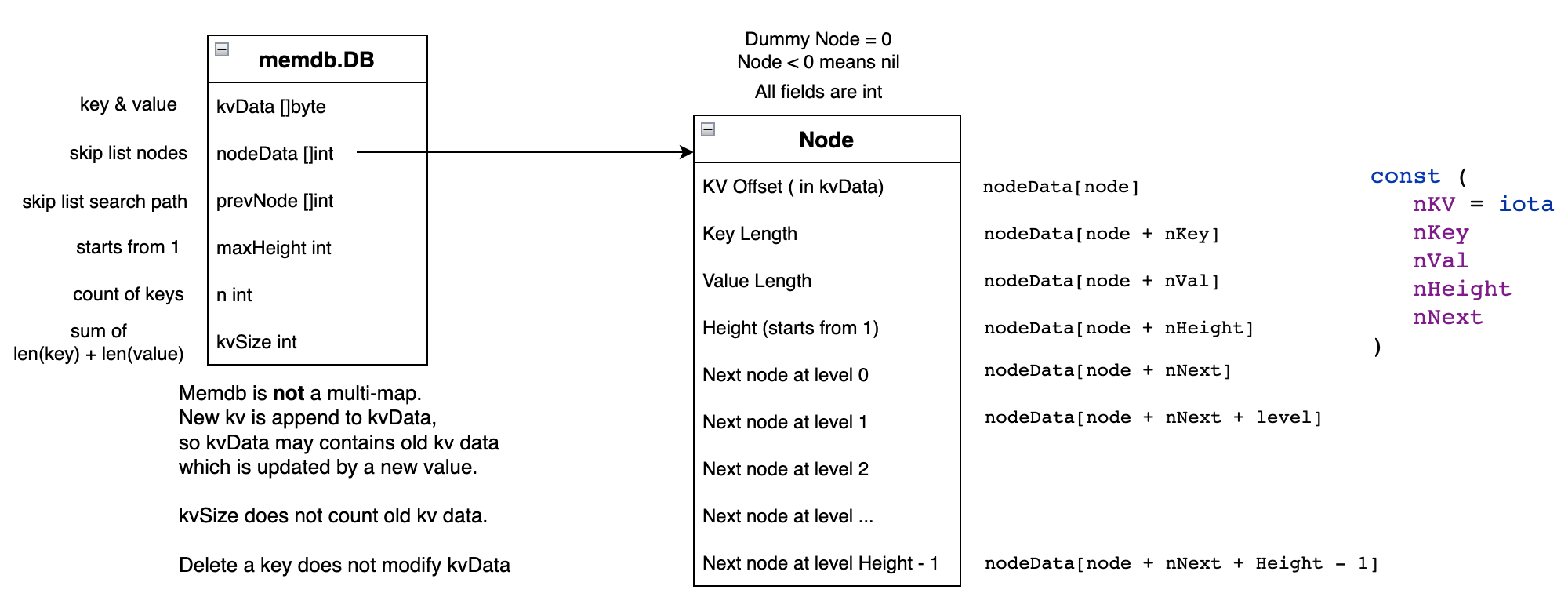
Node < 0 means nill 是错误的,应该是=0。也就是
nodeData[node + nNext + level] = 0 时,表示指向nilkvData 很简单粗暴地按序存储了key (internal key)、value的数据,没有维护任何额外信息,比如长度,MemDB的最大容量也就是kvData的最大容量。nodeData是kvData 中数据对应的SkipList节点,记node为每个节点在nodeData中的偏移量,那么每个节点的结构为:
nodeData[node + nKV]: kvOffset其数据在kvData的位置nodeData[node + nKey]: Key LengthnodeData[node + nVal]: Value LengthnodeData[node + nHeight]: Height 高度,从 1 开始计数nodeData[node + nNext + level]: 各层next指针,其值是下一个节点在nodeData中的offset,level范围是[0, Height - 1]
初始化
初始化MemDB时,会创建一个dummy node,作为最开始的那个节点。其高度为tMaxHeight = 12,各层的next指针都是0,即指向它自己。
Put
首先通过findGE,从dummy node开始,由maxHeight往下找Greate Or Equal待写入的value的节点。不论是否在level0找到,都要移动到level0,并把在每一层中最后一个访问的节点写入prevNode数组中。
为什么要走到level0呢?因为插入数据时,需要重建每一层的链表。我们根据prevNode存储的每一层的节点,即可以完成每一层的链表插入操作。
插入数据时,会随机一个height,范围为[1, tMaxHeight],只会修改[1, height]内的链表。key value数据会append到kvData末尾。
// Put sets the value for the given key. It overwrites any previous value
// for that key; a DB is not a multi-map.
//
// It is safe to modify the contents of the arguments after Put returns.
func (p *DB) Put(key []byte, value []byte) error {
p.mu.Lock()
defer p.mu.Unlock()
if node, exact := p.findGE(key, true); exact {
kvOffset := len(p.kvData)
p.kvData = append(p.kvData, key...)
p.kvData = append(p.kvData, value...)
p.nodeData[node] = kvOffset
m := p.nodeData[node+nVal]
p.nodeData[node+nVal] = len(value)
p.kvSize += len(value) - m
return nil
}
h := p.randHeight()
if h > p.maxHeight {
for i := p.maxHeight; i < h; i++ {
p.prevNode[i] = 0
}
p.maxHeight = h
}
kvOffset := len(p.kvData)
p.kvData = append(p.kvData, key...)
p.kvData = append(p.kvData, value...)
// Node
node := len(p.nodeData)
p.nodeData = append(p.nodeData, kvOffset, len(key), len(value), h)
for i, n := range p.prevNode[:h] {
m := n + nNext + i
p.nodeData = append(p.nodeData, p.nodeData[m])
p.nodeData[m] = node
}
p.kvSize += len(key) + len(value)
p.n++
return nil
}
Update
更新操作和 Put 操作流程一样,只是在 findGE时,能找到equal的节点,进而直接更新节点的kvOffset Key Length Value Length。
不过需要注意的是,并不会更新或者删除kvData中的旧数据,而是仍然在kvData添加新数据。之前的旧值就放在了kvData中保持不动,作为脏数据,没有任何节点指向它。
Delete
删除操作也是先findGE,然后把各层的链表都更新一下,同样地也不会删除kvData中的数据。
Get
Get 操作也是调用 findGE,找到后使用kvOffset Key Length Value Length 把数据从kvData取出来即可。
findGE
下面是 findGE 源码,需要修改链表时,prev才为true,只是Get数据时,不需要走到level0,因此prev = false
// Must hold RW-lock if prev == true, as it use shared prevNode slice.
// returns if equal
func (p *DB) findGE(key []byte, prev bool) (int, bool) {
node := 0
level := p.maxHeight - 1
for {
next := p.nodeData[node+nNext+level]
cmp := 1
if next != 0 {
cmp = p.cmp.Compare(p.keyAt(next), key)
}
if cmp < 0 {
// Keep searching in this list
node = next
} else {
if prev {
p.prevNode[level] = node
} else if cmp == 0 {
return next, true
}
if level == 0 {
return next, cmp == 0
}
level--
}
}
}
Log
(本节内容来自于 https://leveldb-handbook.readthedocs.io/zh/latest/journal.html )
放在内存中的数据并不可靠,当进程崩溃时可能会导致数据丢失。因此再写入内存前会先把数据写到WAL中,当 MemDB 切换到 Frozen MemDB 时,也同时会生成一个 Fronzen Log。当 Frozen MemDB 持久化到文件系统中时,就会把 Fronzen Log 删掉。
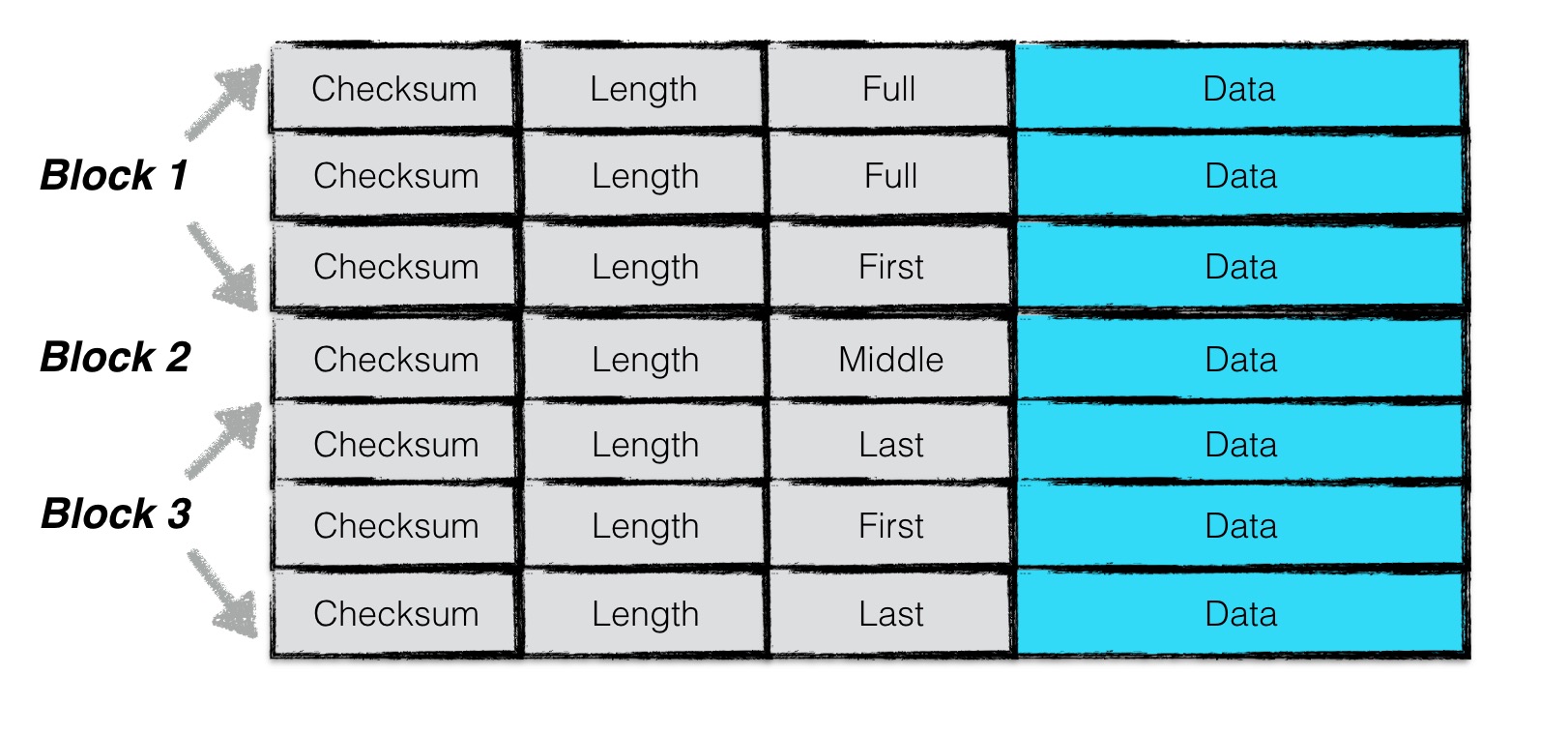
为了增加读取效率,日志文件中按照block进行划分,每个block的大小为32KiB。每个block中包含了若干个完整的chunk。一条日志记录包含一个或多个chunk。每个chunk包含了一个7字节大小的header,前4字节是该chunk的校验码,紧接的2字节是该chunk数据的长度,以及最后一个字节是该chunk的类型。其中checksum校验的范围包括chunk的类型以及随后的data数据。
chunk共有四种类型:full,first,middle,last。一条日志记录若只包含一个chunk,则该chunk的类型为full。若一条日志记录包含多个chunk,则这些chunk的第一个类型为first, 最后一个类型为last,中间包含大于等于0个middle类型的chunk。
由于一个block的大小为32KiB,因此当一条日志文件过大时,会将第一部分数据写在第一个block中,且类型为first,若剩余的数据仍然超过一个block的大小,则第二部分数据写在第二个block中,类型为middle,最后剩余的数据写在最后一个block中,类型为last。
(完)
References: