
想要运行一个Java程序需要经过三个阶段:编写源代码—编译—在JVM上运行。那么一个字符串在以上三个阶段的编码方式是怎样的呢?另外,如果Java程序中要输出字符串,那么输出的字符串的编码又是什么呢?
1. 在源代码中的编码
编写Java源代码时,我们一般会打开一个文本编辑器或者是IDE,然后使用系统输入法键入代码,编写完成后以某种编码方式将源代码保存到磁盘上。
1.1 输入法到编辑器
在键入字符串,如你好,世界时,操作系统会告诉输入法键盘上哪些键被按下了,这样输入法就确定了要输入的字符串,接着输入法把选定好的字符串传给编辑器。
输入法传递给编辑器的字符串是什么编码呢?应该是系统的默认编码。
编辑器打开源代码时,都会有一个默认的编码,只是保存时可以选择以其它编码方式保存。编辑器接收到输入法传过来的字符串后,会将其从系统默认编码转换为当前文件的编码,同时将其显示到屏幕上。
1.2 编辑器到磁盘
保存文件时,需要指定文件的编码方式,也就是将整个.java文件中所有字符都按照指定编码格式转换成16进制的字节数组。
class Hello {
public static void main(String[] args) {
System.out.println("你");
}
}
把上述代码按UTF-8保存,可以看到,字符H被编码成0x48,也就是72,与ASCII码表中H的值相同。字符你被编码成0xE4BDA0。查询UTF-8码表可以发现该0xE4BDA0对应的就是字符你。
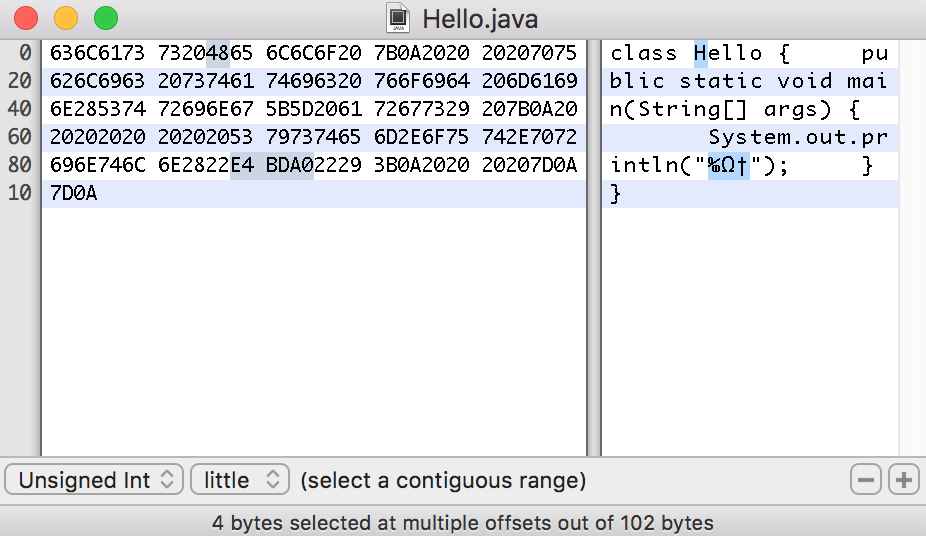
当把上述代码按GBK编码保存时,字符H依然是0x48,而字符你变为0xC4E3,相对于UTF-8的三个字节,使用GBK编码只需要两个字节就能表示字符你。查询GBK码表可以发现,0xC4E3对应的字符就是你。
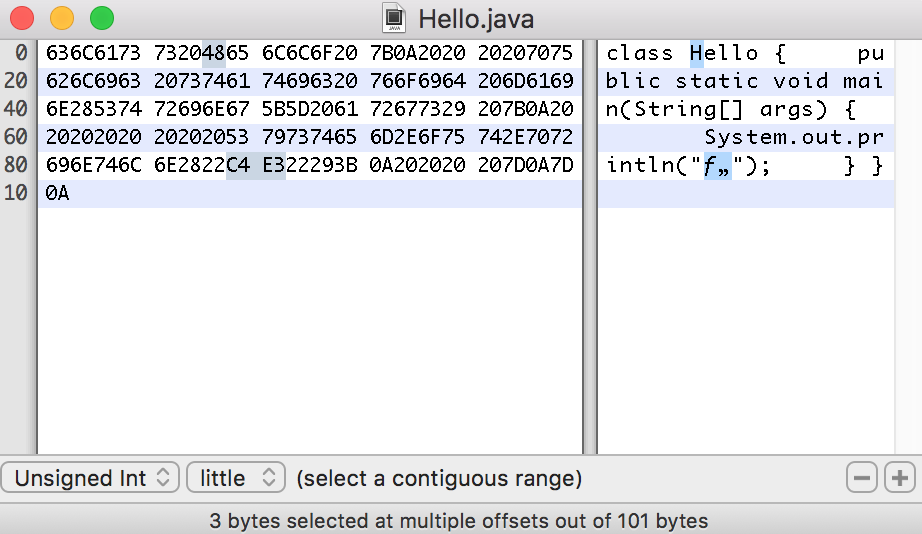
1.3 编译源代码
所以,按不同编码方式保存的.java文件中,字符串的表示方式会有所不同。那么Java编译器是怎么识别这些不同编码方式的源文件的呢?
其实并没有自动识别,javac在读取源代码时,默认使用系统默认的编码方式读取代码,要是遇到无法解析的字符时,就会报错。若要编译其它编码的源文件,就需要在编译时指定编码,如javac -encoding GBK。
1.4 总结
总结而言,Java字符串在.java文件中的编码方式与保存文件时使用的编码方式相同。存储到磁盘上时,以码表中该字符对应值的二进制形式存储。
2. 在.class文件中的编码
既然源文件的编码方式有多种,那么编译之后生成的.class文件会不会也有多种编码方式呢?答案是否定的,经过编译之后,不论是字符串还是标识符,源代码中所有字符都以Modified UTF-8形式存储在.class文件中。


3. 在虚拟机中的编码
上面讲到源代码中所有标识符与字符串都是以Modified UTF-8形式存在.class文件中,那么当JVM执行.class文件时,在JVM内部以什么形式表示字符串呢?
在JVM内部以Unicode形式表示字符串。JVM会将.class文件中的字符串读取出来,将其转换为Unicode字符。转换方式见DataInputStream.readUTF(DataInput in)。
每个字符串都以char数组的形式存在。对于\u0001-\uFFFF范围内的字符,用一个char表示;对于\u10000-\u10FFFF范围内的扩展字符,用两个char表示。

3.1 扩展字符编码示例
在\u0001-\uFFFF范围内的字符编码方式很好理解,因为只需要用两个字节就能表示,而char类型大小正好是两个字节。
但是大于\uFFFF的扩展字符就需要用两个char来表示了,比如字符 𐐀 (\u10400)。那么字符 𐐀 应该怎么用两个char表示呢?java.lang.Character提到了,扩展字符用对应的UTF-16值表示。字符 𐐀 对应的UTF-16值为\uD801\uDC00,故用这两个字符表示。
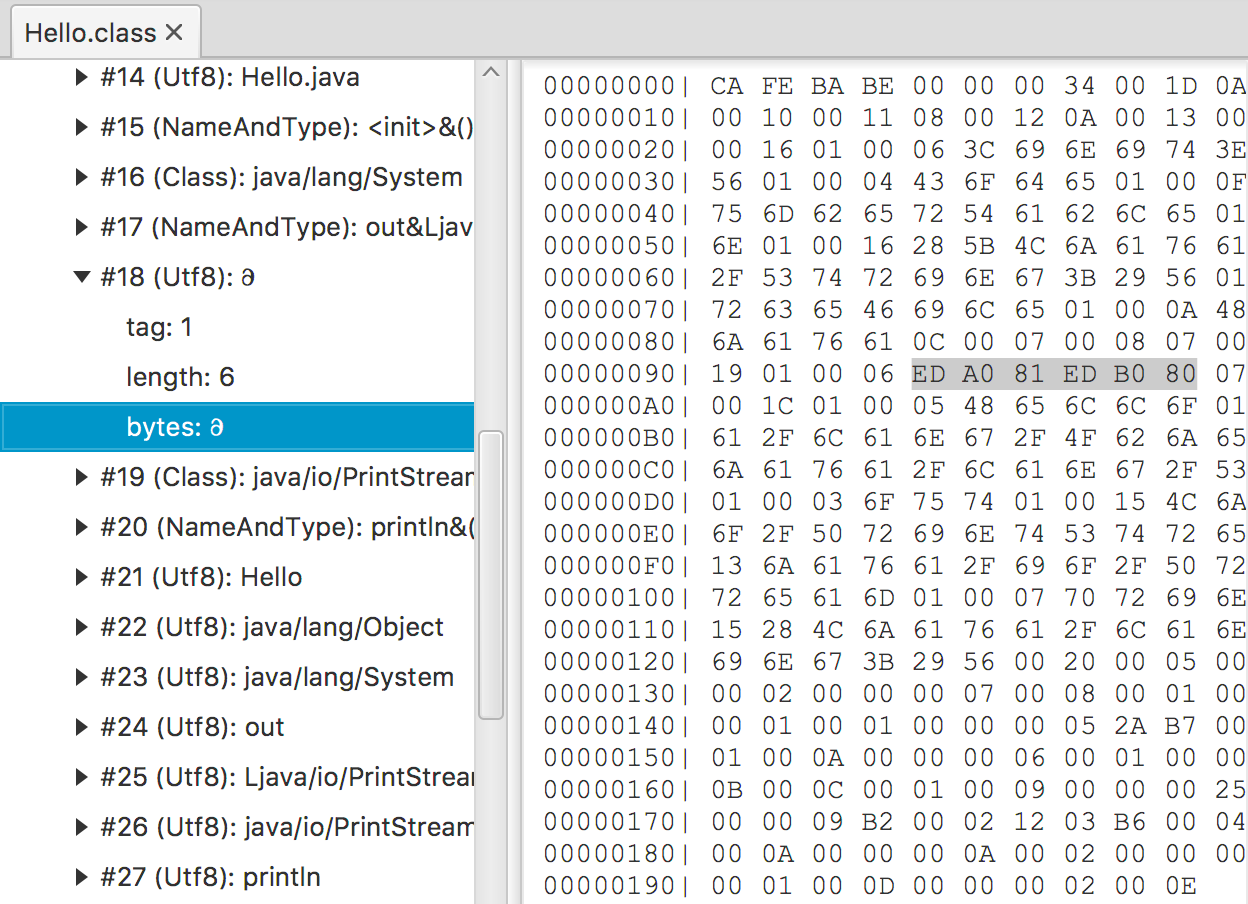
用classpy可以查看编译之后的.class文件内容。可以看到字符 𐐀 用Modified UTF-8编码时,其对应的值为\xEDA081EDB080,利用第二节所述的Modified UTF-8转Unicode规则,可以有如下转换

故其Unicode值为66560,即为0x10400。查询UTF-16码表,可以找到对应的UTF-16值为\uD801 \uDC00。
这样,JVM就完成了字符 𐐀 的编码,在JVM内部的表现形式为char[] value = {'\uD801','\uDC00'}

4. 程序输出时的编码
尽管在JVM内部字符串用Unicode表示,但是输出时总要指定一种编码。使用System.out进行输出时,使用的是系统默认的编码。可以更改sun.stdout.encoding的值进行更改。

参见 System.initializeSystemClass()

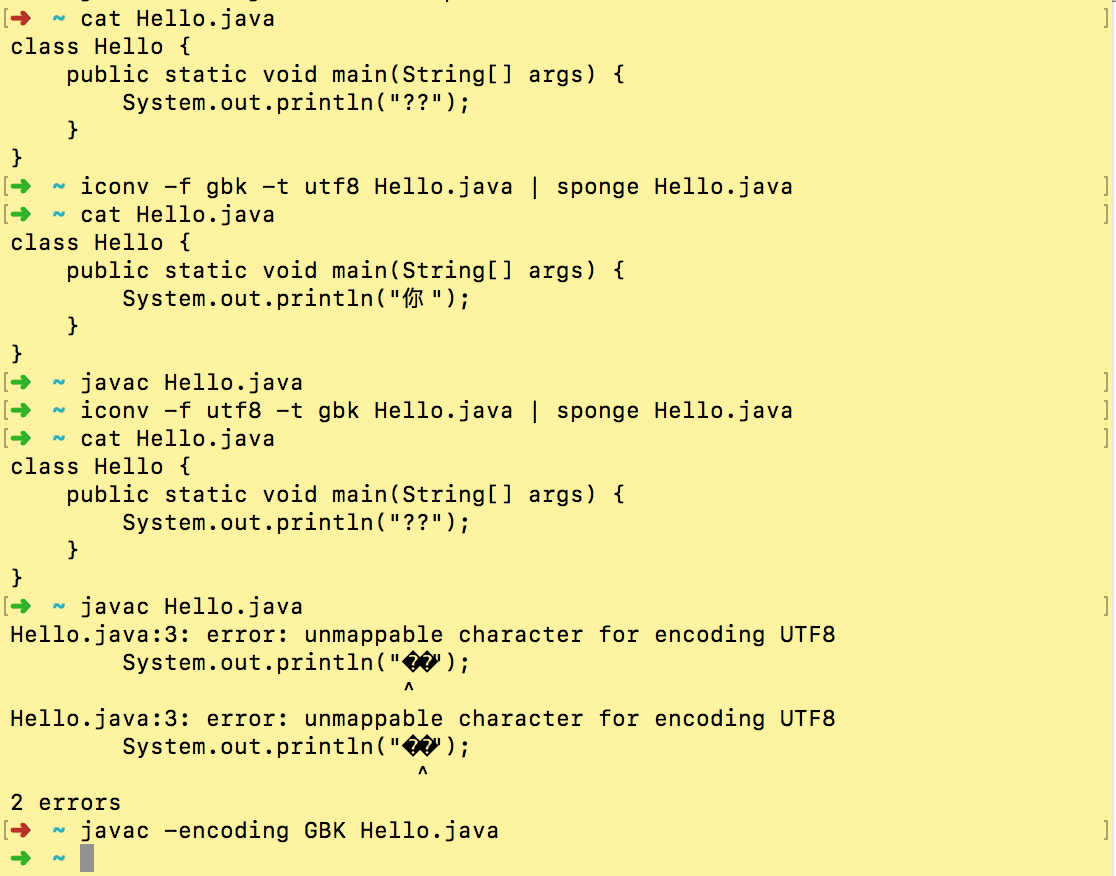
如图所示,系统以及控制台默认编码是UTF-8,故第一次能够成功输出;第二次运行使,更改输出编码为GBK,导致控制台无法使用UTF-8编码识别输出的字符串,故而显示乱码。
总结而言,程序输出时可以自行指定编码。
文中码表指的是,用不同的编码方式编码Unicode字符时,各个Unicode字符对应的二进制表示形式。编码方式不同,则同一字符对应的二进制不同。
把字符表示成二进制形式,是为了便于存储于传输。在程序运行时,一般都用Unicode表示字符串。那为什么不全都用Unicode算了呢?因为Unicode字符至少得用两个字节表示(U+0000到U+10FFFF,一一对应),会造成空间浪费(ASCII只需要一个字节),也会降低传输效率。故而产生了各种变长编码。
(完)