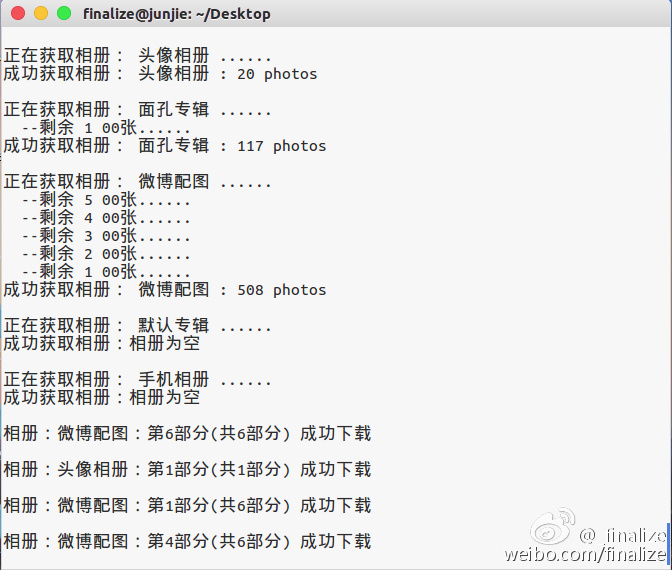
weitu.py Record
起因
清明节闲得无聊,想找些美女图片看看,于是想到用python爬微博图片
经过
登录新浪微博
尼玛登录都需要rsa加密神马的,不知道怎么搞,上网搞的代码
获取相册信息
原以为只要GET到相册首页就可以用正则表达式提取相册URL的,把GET到的源代码下载到本地打开一看,我勒个擦,居然显示个正在加载!!!
没想到尼玛居然使用JS加载的图片。
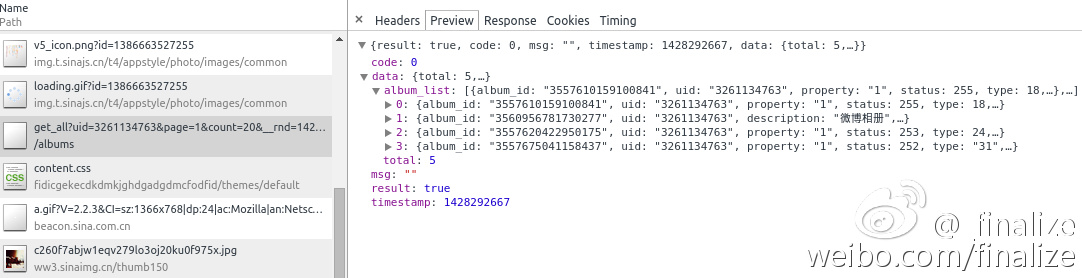
用Chrome单步调试,发现了一个诡异的JSON文件,点开一看,我勒个擦,相册信息居然全在里面!
'http://photo.weibo.com/albums/get_all?uid=%s&page=%d&count=20&__rnd=1428293011117' % (uid , page)
获取照片信息
解析上面的JSON文件(gallery_JSON),可以获得album_id
然后随便点进去一个相册,也可以获取到另一个JSON(album_JSON)文件,里面是该相册所有照片的信息
'http://photo.weibo.com/photos/get_all?uid=%s&album_id=%s&count=30&page=%d&type=%s__rnd=1428293319045'%(uid, album_id, page, theType)
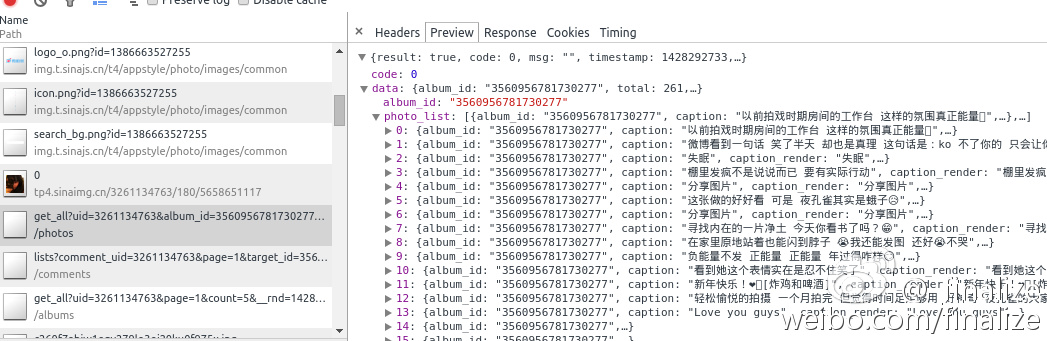
从中可以提取到photo_id,然后就可以进入大图页了

观察了一下图片URL规则
对于微博配图
'http://photo.weibo.com/%s/wbphotos/large/photo_id/%s/album_id/%s'%(uid,photo_id,album_id)
对与非微博配图
'http://photo.weibo.com/%s/photos/large/photo_id/%s/album_id/%s'%(uid,photo_id,album_id)
然后GET进该URL,可以从中提取图片的实际URL,如
http://ww1.sinaimg.cn/large/c260f7abjw1eqtlx58y4zj20qo0zkn2g.jpg
{kind=link}
问题
省略URL
作死的我把gallery_JSONURL中的__rnd=... 和album_JSONURL中的type=18&__rnd=1428293319045给删了
然后就发现微博配图获取到的照片为0
于是果断地加上type,type可以在gallery_JSON 中获取,至于__rnd,我认为就是random,删了算了
效率问题1
看了看JSON文件URL中有count=...page=...
这尼玛该不会是数据库分页查询吧?
果断把count改成500试试,我擦,bug了。。。
试了几次,发现100能确保安全。那就把gallery_JSON album_JSON中的count都改成100
减少GET次数,节约时间咯
效率问题2
由于每张照片都要先GET进图片详情页,再用正则表达式提取图片真实地址,这样会耗费大量的时间
我特么就想了想,难倒就不能直接搞到图片的URL么?
观察了一下,photo_id是这样的3827939823006128
而图片实际地址中pic_id是这样的c260f7abjw1eqtlx58y4zj20qo0zkn2g
难道有什么算法可以把纯数字ID加密成一堆无意义的字符串?
我特么就想试试加密算法,先百度了个MD5在线加密,加密之后却不对
尼玛,难道要让哥一个个地试么?要是他喵的新浪自创的一个算法那该怎么办?
解决
冷静了一下,想想要不再从JSON文件里面找找信息?
果然,,答案就在album_JSON文件里面(已哭瞎!!!)
pic_host pic_name pic_id 一目了然
URL=pic_host/large/pic_name 次奥尼玛!
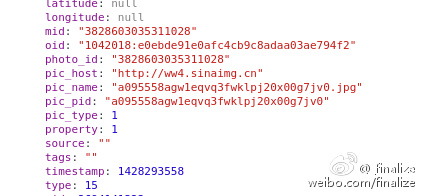
成功get图片URL
要不先GET一下女神黄灿灿?:)
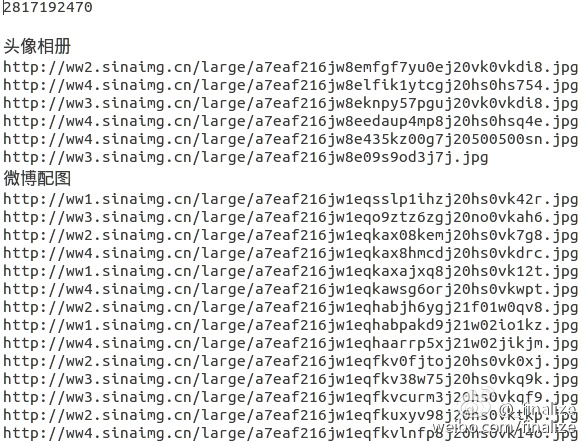
多线程下载图片到本地
本来想只搞到URL然后再用迅雷下载的,后来发现迅雷下载很麻烦,还要复制粘贴分文件夹什么的,就放弃了
又想到不如调用wget下载吧?又懒得去看wget文档
于是就自己写咯
每100张图片分一个线程下载,最后(嘻嘻嘻嘻)
下载图片时使用线程池
利用threadpool库,开启线程池,初始化10个工作线程
当照片数达到1000时,或者相册总数达到10时,使用线程池下载。因为对于每个相册,即使里面的照片不足100,也会开一个线程下载。因此要限制相册数量
HaHaHa~