- 列式存储怎么存数据?
- 按列存储,有多少个字段就有多少个数据文件
- 怎么查询出某一行?
- 按照主键排序,知道数据在主键 Column 的哪一行,其它字段对应的行数和它一样
- 主键索引的格式是怎样的?和 B+-Tree 有什么区别?
- 稀疏索引,每 Granule 条数据记录一条索引项,且该索引项中各字段并不一定属于同一行
- 主键索引会全部加载到内存中,采用二分查找来定位数据属于哪一个 Granule
- 找到 Granule 后,通过遍历来查找数据,而不是精确到某一行
- 相比于 B+-Tree,减少内存占用、加快写入效率
- Granule 中只有数据项,还要通过其对应的
.mrk文件找到其在.bin文件中的 Block 位置
- 主键如果有多个字段,其顺序会影响查询速度吗?
- 顺序影响效率,因为是按其排序并存储数据的
- 可以建立多个不同字段顺序的索引,但是会导致存储空间翻倍,有3种方式建立
- 建议低粒度的字段放在前面,可以增加压缩率
- 其它字段可以建索引吗
- 其它字段也可以建索引,最常用的是 minmax、bloom filter 等其他几种
- 主要目的是为了过滤数据,也就是过滤掉哪些一定不在结果集中的Granule,称其为 Data Skip Index
1. Columnar storage
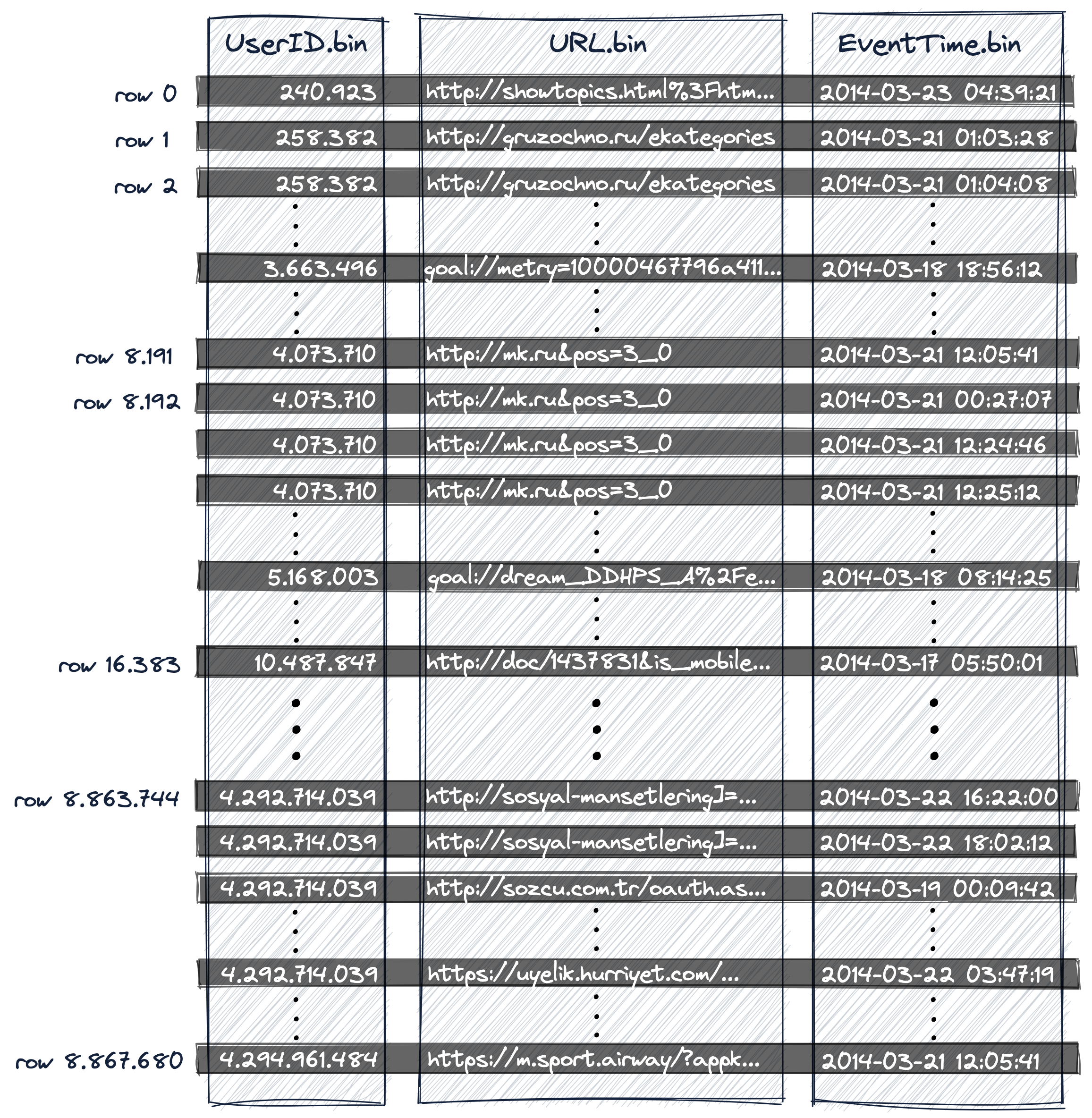
与 MySQL、PostgreSQL 等传统的关系型数据库不同,ClickHouse并不是按行存储数据的,而是按列存储。以 Excel 表格为例,按行存储会将一整行作为一个整体写到同一个文件中,而按列存储则会把各列数据分开存储到不同文件中。
那么问题来了,按列存储时,怎么应对查询出某一行的所有列这种需求呢?各列都是分开存放的,怎么知道哪些数据属于同一行呢?按列存储到底是怎么个存储法?还是以 Excel 为例,Excel 有按列排序的功能,排序时,会让我们选择要不要把其他列也随着被选中的列进行排序。这种其它列跟随某些列进行排序的思路,就是 ClickHouse 按列存储的基本原理。
在 ClickHouse 中,虽然各列数据分开存储,但是都是按照主键的顺序排好序的。同一行数据,在各个列中的行号都是相同的。可以理解为先按照关系型数据库的方式,按行排好序,然后把各列数据分开存储。在查询时,只需要根据查询条件找到其所属哪一行,就能在各个列文件中找到该行对应的所有数据了。
CREATE TABLE hits_UserID_URL
(
`UserID` UInt32,
`URL` String,
`EventTime` DateTime
)
ENGINE = MergeTree
PRIMARY KEY (UserID, URL)
ORDER BY (UserID, URL, EventTime)
比如有 hits_UserID_URL 表,其数据就是按下面的方式存放的:
2. Primary Index
前面我们提到了主键,当然比不可少的会有主键索引,那么主键索引的存储格式是怎样的呢?是和传统关系型数据库一样,使用B+树吗?结论是否定的。数据在 ClickHouse中的最小粒度称为 Granule,一般是 8192 行。主键索引的对象是 Granule,也就是每个索引项对应一个 Granule,是无法像B+树那样做到每一行都有对应的索引项的。
(Granule 只是逻辑结构,数据并不是以 Granule 为单位存储的,详见 ClickHouse存储引擎之MergeTree引擎——数据存储)
一条主键索引项,存储的是数据在其对应的 Granule 中的最小值(最后一个 Granule 存最大值)。如果主键有多个字段,那么索引值并不来自于同一行数据,而是分别存储各个字段的最小值。ClickHouse 的思路并不是精确查询数据,而是判断数据属于哪一个 Granule。

索引数据存放在.idx文件中,运行时会全部加载到内存。查询时,通过二分查找来定位 Granule。找到 Granule 后,需要找到其在数据文件中对应的位置,这些信息记录在 .mrk文件中。找到位置后,把整个 Granule 读出来,遍历一下就知道所要查询的数据在哪一行了。
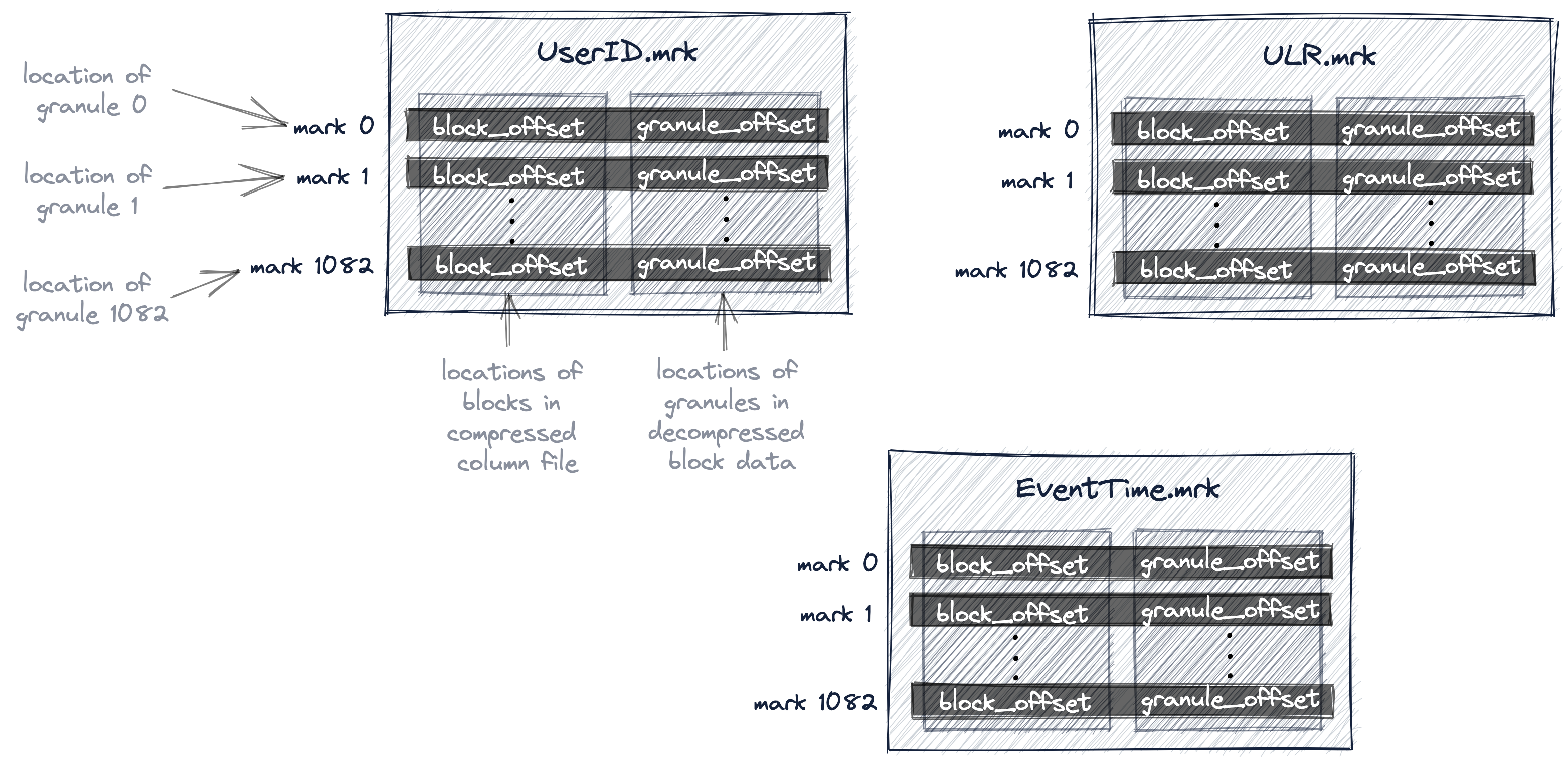
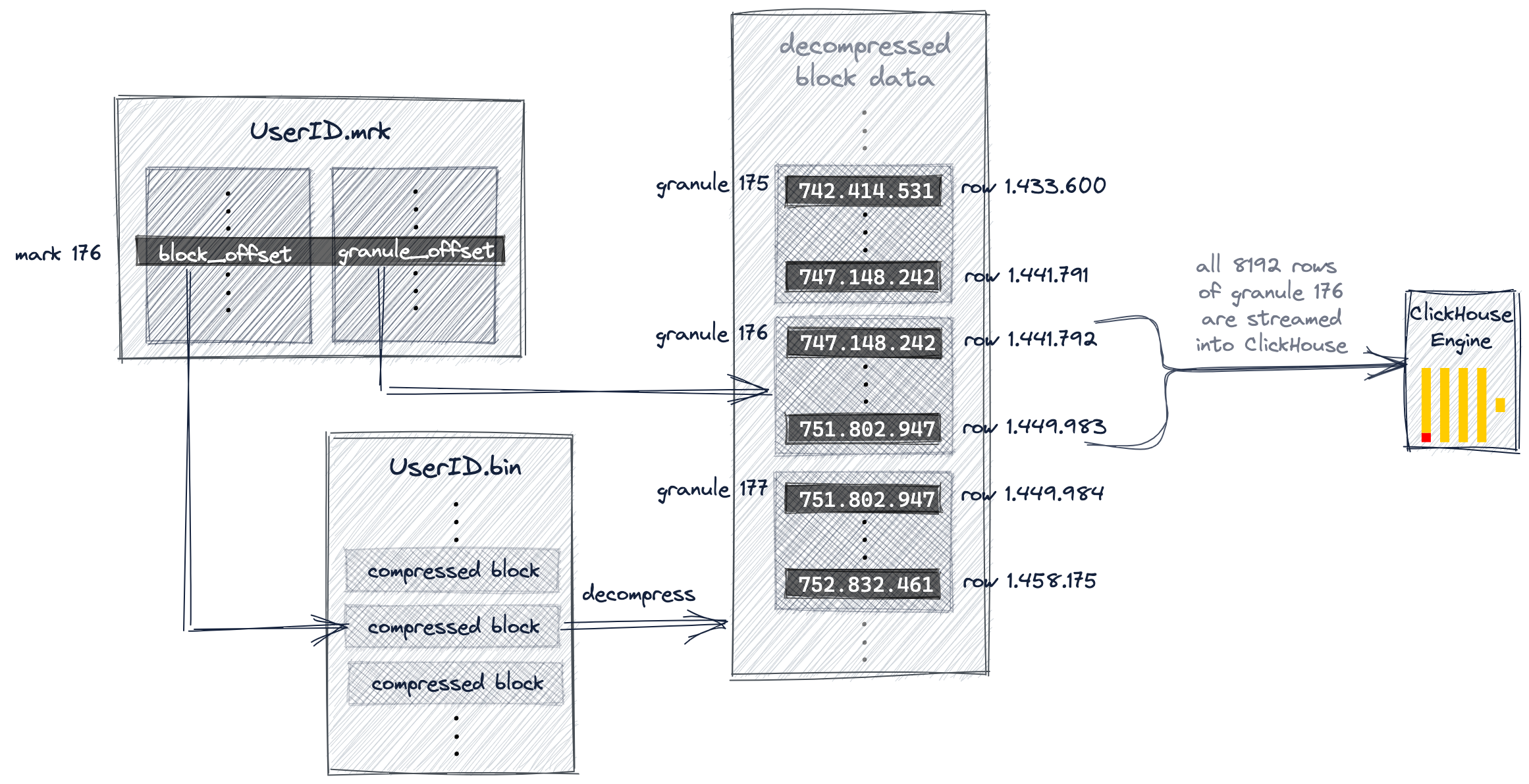
3. Multiple Primary Index
主键如果有多个字段,其顺序是会影响查询速度的。比如 hits_UserID_URL 这个表,主键是 (UserID, URL),那么你通过 UserID 查询的话,速度会很快,因为只需要在主键索引中根据 UserID 来进行二分查找就好了。但是通过 URL 查询的话,就不太行了,即是主键中包含了URL,但是其在UserID 后面,就没办法用二分查找了。详见 Using multiple primary indexes
为了解决顺序问题,可以再创建一张新表(hits_URL_UserID),数据相同,但是主键字段的顺序不同。一共有三种方法,本文就不展开了,可以去看下官方文档:
- Secondary Tables:需要用户手动维护第二张表,包括写入和查询
- Materialized Views: 会自动往第二张表写数据,但是查询时还是需要指定第二张表名
- Projections:用户完全无感知,会自动往新表写数据,查询时,会自动判断要走新表还是旧表
4. Data Skip Index
除了主键索引外,还可以给其它字段建立索引。其它非主键索引的核心思想就是,尽可能地用这类索引来过滤掉一定不包含查询结果的Granule。因此称之为 Data Skip Index,某个查询 Skip 掉的 Granule 越多,查询效果也就越好。主要有以下几种类型:
- minmax
- set
- Bloom Filter
5. File Structure
ClickHouse的文件结构比较简单,都是以文件表示数据库结构:
/var/lib/clickhouse/metadata/{db_name}/{tb_name}.sql存建表语句/var/lib/clickhouse/data/{db_name}/{tb_name}该目录存数据文件
数据按照 partition 进行组织,由于 MergeTree Engine 是基于 LSM Tree,因此同一个 partition 可以有很多层。命名格式为 {partition}{min_block}{max_block}{level}_{data_version}
每个 partition 中又包含以下数据:
columns.txt:各个字段名,相当于表头count.txt:整个 partition 下的数据总行数primary.idx:主键索引{column}.bin:各字段数据{column}.mrk:各字段对应的mrk文件{secondary_index}.idx:非主键索引
(完)
References: