如果你特别特别喜欢一个B站UP主,想要下载她的所有视频,防止她删库跑路,那么这篇文章就很适合你!
原理是:先去动态页面把所有的视频链接搞到,然后再用 BBDown 下载。
使用姿势:
下载BBDown 到本地(linux-x64版本),使用 ./BBDown login 登录下(不登录也行,登录才能下载最高画质)。
最后找到你想要下载的 UP 主的 ID(个人空间URL中的ID),比如佩奇科娃的ID是 1646036311 ,29363157 执行
$ ls
BBDown bili.py
$ docker run --rm -it -v `pwd`:/data --entrypoint=/bin/bash jrottenberg/ffmpeg:4.4-ubuntu
root@8d444b8c7794:/tmp/workdir# cd /data
root@8d444b8c7794:/data#
root@8d444b8c7794:/data# apt install python3-pip --no-install-recommends -y
root@8d444b8c7794:/data# pip3 install requests
root@8d444b8c7794:/data# python3 bili.py 29363157
视频就能下载到本地啦。(默认下载最高画质哦)
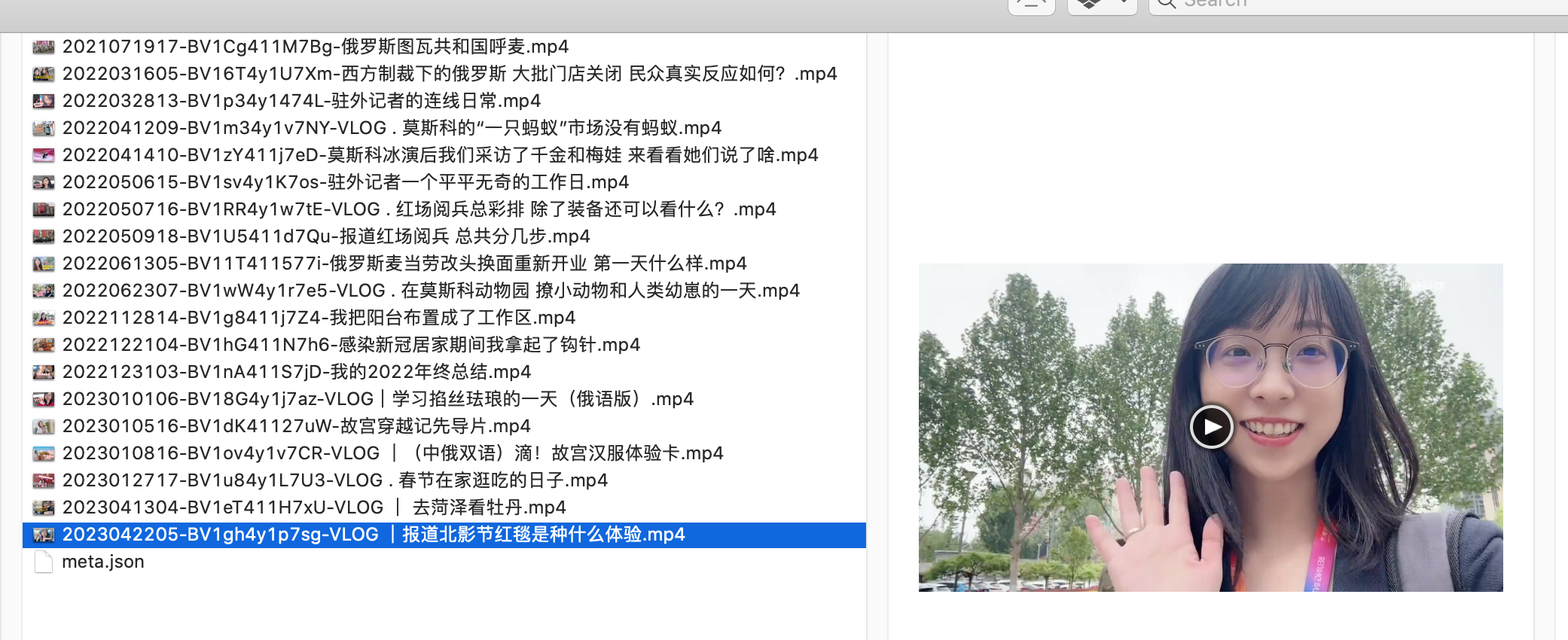
附 bili.py 源代码:
import requests
import time
import sys
import os
import json
import re
from datetime import datetime
session = requests.Session()
session.headers.update({'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/15.1 Safari/605.1.15'})
def download_videos(host):
offset = ''
has_more = True
videos = []
all_items = []
while has_more:
url = f'https://api.bilibili.com/x/polymer/web-dynamic/v1/feed/space?offset={offset}&host_mid={host}&timezone_offset=-480&features=itemOpusStyle'
data = session.get(url).json()['data']
has_more = data['has_more']
offset = data['offset']
items = data['items']
for item in items:
t = item['type']
if t == 'DYNAMIC_TYPE_AV':
ts = item['modules']['module_author']['pub_ts']
ctime = datetime.strftime(datetime.fromtimestamp(ts), '%Y%m%d%H')
detail = item['modules']['module_dynamic']['major']['archive']
url = detail['jump_url'].replace('//', 'https://')
vid = re.search(r'/video/(\w+)/', url).group(1)
v = {'title': detail['title'], 'url': url, 'vid': vid, 'ctime': ctime}
videos.append(v)
print(v)
all_items.extend(items)
time.sleep(1)
if not os.path.exists(host):
os.mkdir(host)
with open(f'{host}/meta.json', 'w') as f:
json.dump(all_items, f)
for v in videos:
cmd = f""" bash -c 'cd {host} && ../BBDown {v['url']} -dd --Video-only -F "{v['ctime']}-{v['vid']}-<videoTitle>" -M "{v['ctime']}-{v['vid']}-<videoTitle>-<pageNumber>-<pageTitle>" ' """
print(cmd)
os.system(cmd)
if __name__ == '__main__':
download_videos(sys.argv[1])
Update
可以下载弹幕哟