使用 Prometheus 也有两年了,一直很好奇它是怎么存储数据的:不仅能按时间范围查询,而且还能用各种 label 值进行过滤。于是研究了下,发现原理还是挺简单的。
在介绍数据存储格式时,首先我们要明确以下几个概念:
Metric: 也就是指标Label:Metric附带的标签,比如metric{service="gunicorn", protocol="https"}中的servie、protocol。Series:指的是metric name以及其所有附带的 label-value 对。例如metric{A="a"}和metric{A="a", B="b"}是两个不同的Series。Sample:Series在某个时间点的值
很显然,我们会按时间顺序写入Sample,并且会按时间和Label进行查询。最简单粗暴的方式是,每个Series都单独用一个文件来存储,新来的Sample往其对应的文件末尾追加。但是这种方式有几个问题:
- 可能会用尽inode
- 同时打开的文件描述符可能会过多
- 会有频繁的文件写入
- 查询时,各种标签的组合过滤不好实现,因为要跨文件
- 数据过期不太好实现
Chunk
因此,为了减少inode及文件写入数量,需要把来自多个不同Series的Samples进行聚合,最简单的方式是按照时间聚合,聚合的结果称之为Chunk tsdb/docs/format/chunks.md。也就是把多条Sample作为一个基本单位,进行读写。另外,Chunk 会经过压缩,以节约存储空间。

https://ganeshvernekar.com/blog/img/tsdb9.svg
{kind=link}
新写入的数据会先写入Head和WAL,Head相当于一个内存缓冲区,当数据量累积到一定数目或超过一段时间后,会将数据写到磁盘文件中。由于局部性原理,最近新产生的Sample有更大的概率被访问,因此会通过M-map打开。当M-map区域的 Chunk 数量超出限制时,会将其移出去,生成真正持久化的版本:包括数据文件和索引文件。
Index
Chunk混入了多个不同Series的数据之后,那要怎么根据Label来查询呢?这时候我们就需要引入Index了。Index单独放在另一个文件中,目的就是加快根据Label的查询速度,包括等于、不等于、包含、正则、逻辑与或非等等复杂查询。
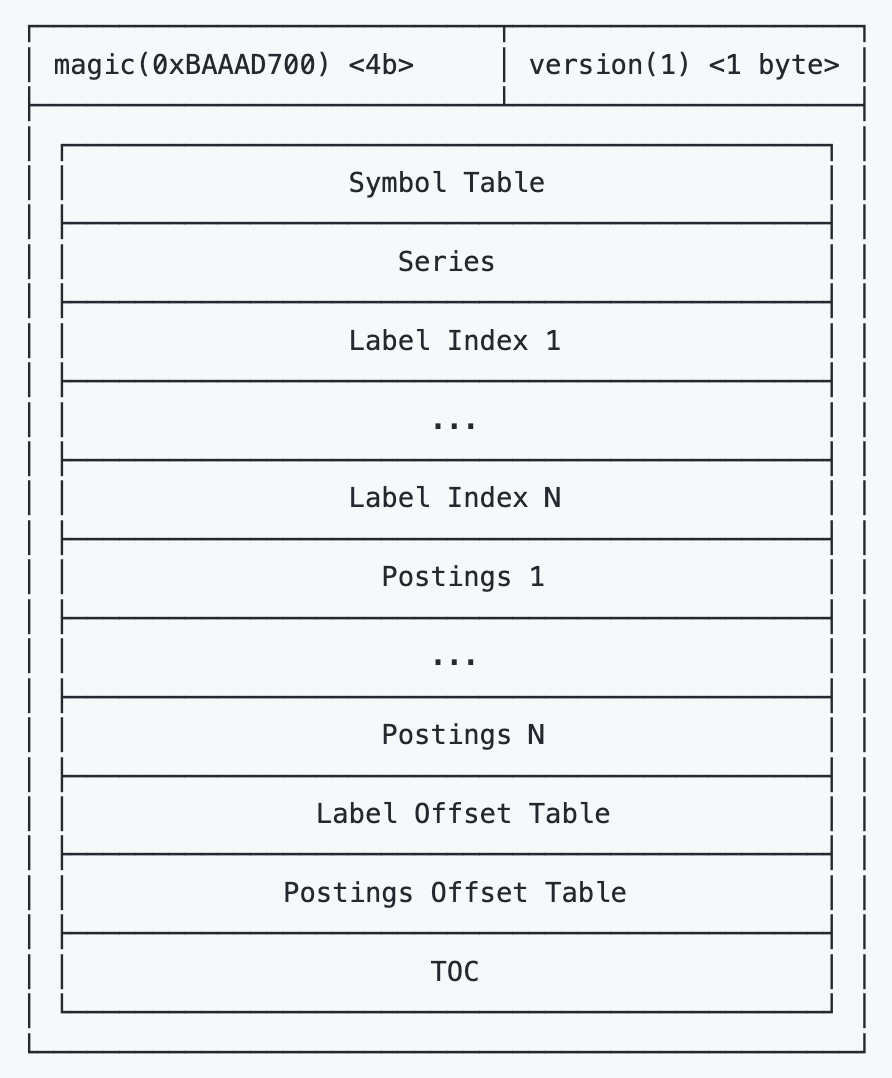
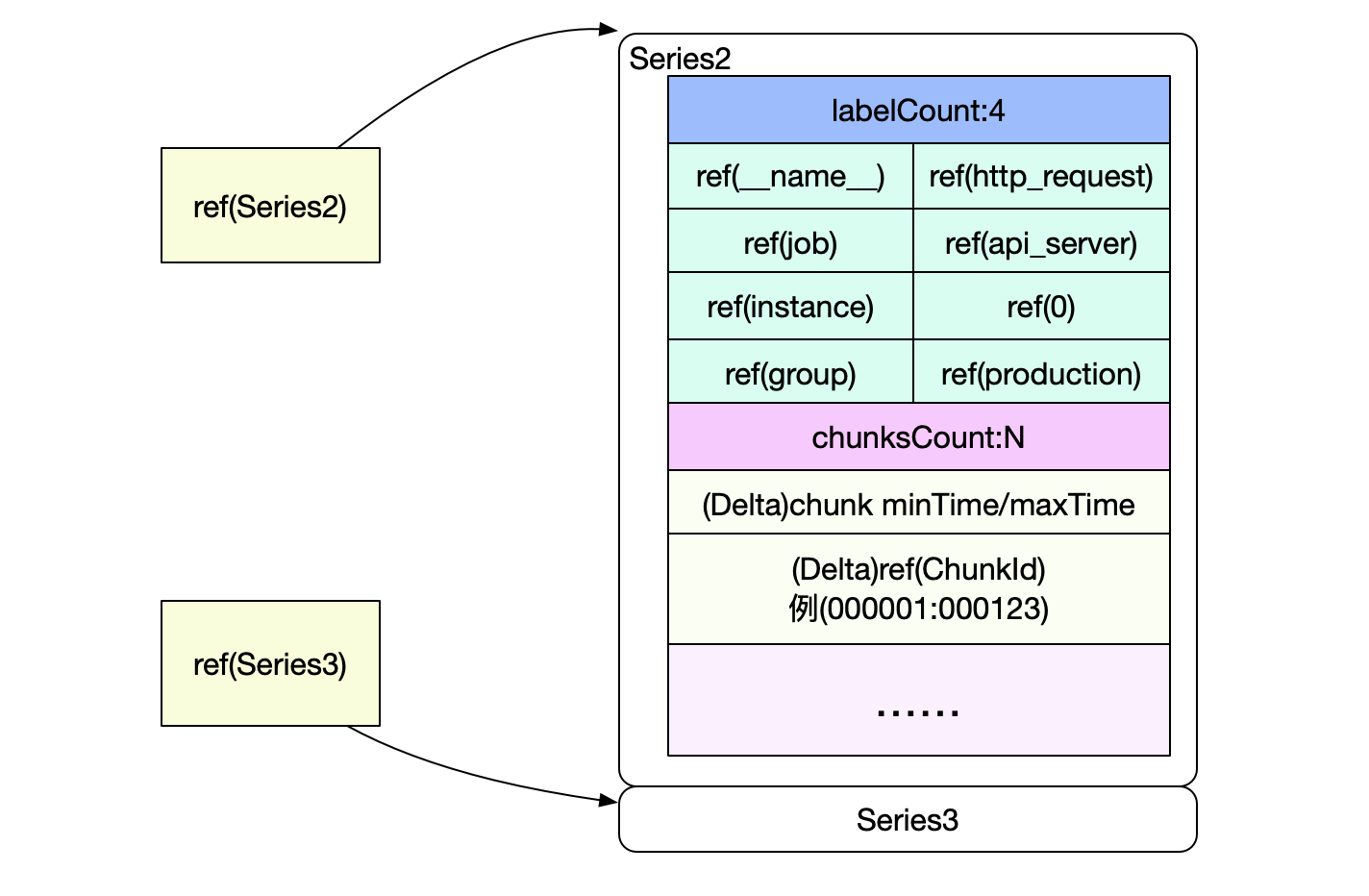
Index文件的结构如上图,包括了很多部分,但是核心是倒排索引。类似于新华字典,对于所有的 Label-Value pair都记录了其在数据文件中的位置,在查询时,就可以进行查表,找到对应的数据。
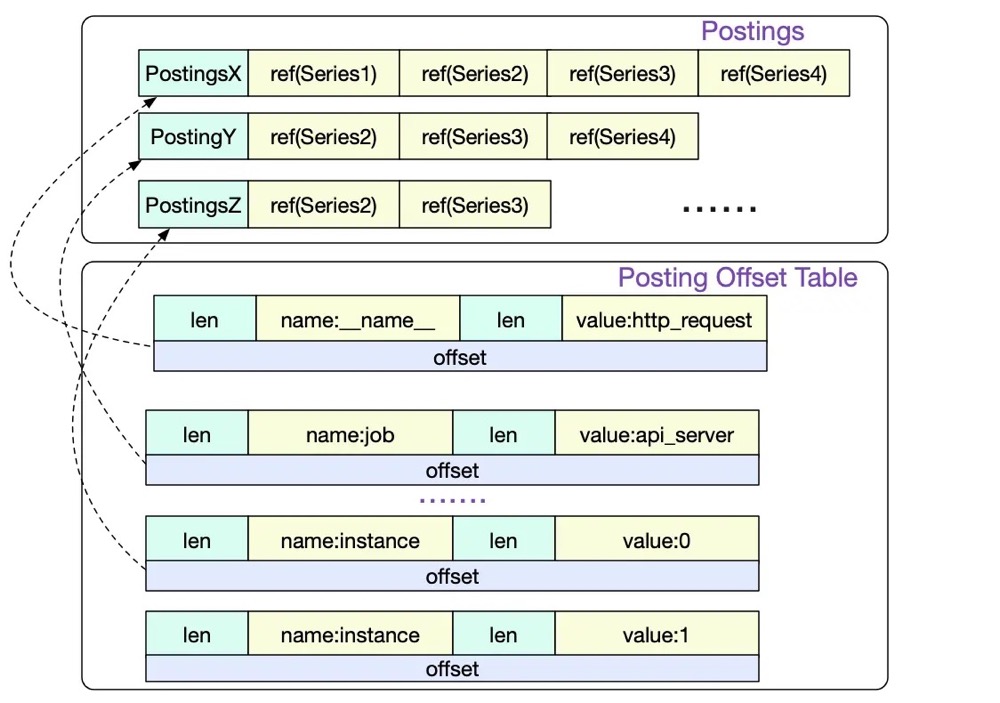
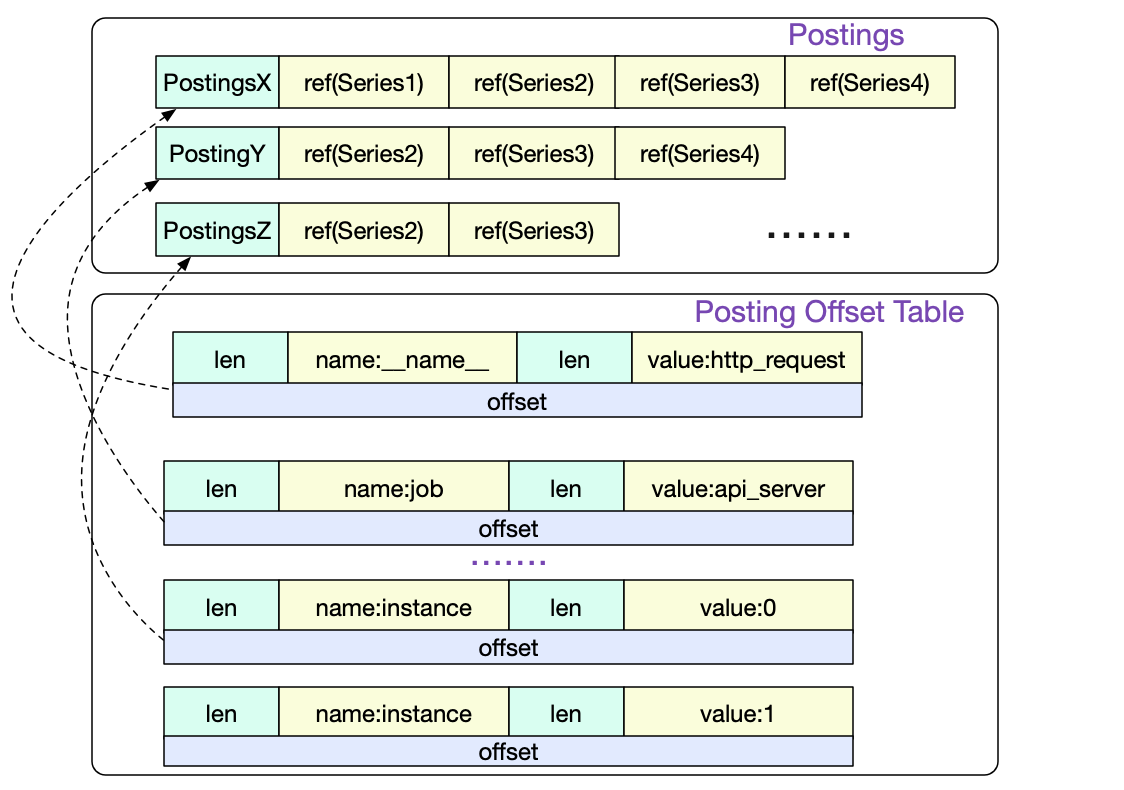
Symbol Table: 包括所有出现的字符串,去重后按序存储,目的是节省存储空间Series: 存所有Series及所有包含它的Chunk的位置Label Index: 存所有Label及其所有Value的值,目的是支持对Label进行正则匹配等非精确查询。Label Offset Table: 存每个Label在Label Index中的开始位置Postings:就是最关键的倒排索引了,每个索引项都存储了其关联的SeriesPosting Offset Table:存每个Label-Value pair在Postings的开始位置
https://oscimg.oschina.net/oscnet/up-0b7a401836c5b8e549501f9ab6fc2161025.png
{kind=link}
https://oscimg.oschina.net/oscnet/up-ede75bbb021a5450c9d1a18bb8f7bdf0202.png
{kind=link}
查询时,会首先把Index中的内容加载到内存中,但并不会把所有的Posting都加进去,为了节省内存,会按顺序隔几个加载一次。然后会用二分查找来查询Label在Posting Offset Table中最近的位置,然后再查表,找到精确位置。大概就是这么个数据结构:
posting map[string][]postingOffset
type postingOffset struct {
value string
offset int
}
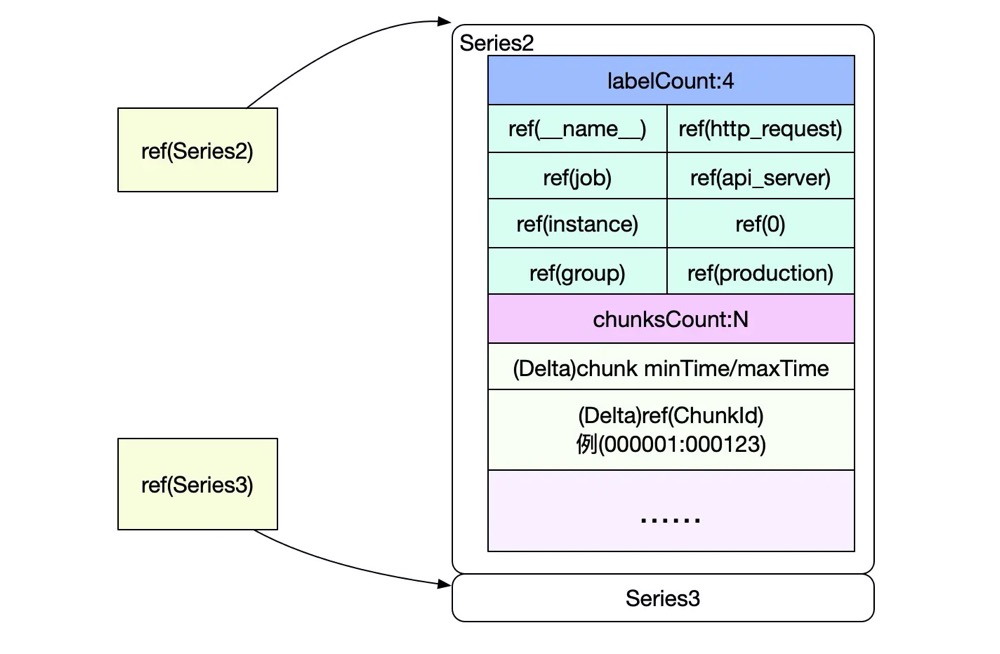
比如我们要查询metric{A="a", B="b"},那么根据Posting Offset Table即Postings,我们查出:A=a 出现在Series [1, 3, 5, 6, 8, 9, 10] 中,B=b 出现在Series [3, 4, 5, 11, 23] 中。二者求交集, 得出{A="a", B="b"} 出现在Series [3, 5] 中。而Series记录了其对应的Chunk在数据文件中的位置以及时间范围,那么就可以确定某个具体的Sample在数据文件的哪里了。
(特别的metric也作为特殊的Label进行存储记为__name__="metric")
File Structure
有了上述知识背景后,就能看明白 TSDB 的文件结构了:
chunks_head: 通过 mmap 打开的数据文件,没有关联的索引文件01GHQEVXYVJ9EQ4Z0JWS7EY545: 类似这样命名的文件称之为Block,相当于一个小型的TSDB,存放了一段时间的数据,多个 Block 可以合并为一个。其中包含了数据文件、索引文件、元信息等。wal: 存放 WAL 和 checkpoint 等信息
storage_v2/
├── 01GHQEVXYVJ9EQ4Z0JWS7EY545
│ ├── chunks
│ │ └── 000001
│ ├── index
│ ├── meta.json
│ └── tombstones
├── 01GHQEVZ468HWPJ9QMD065FP61
│ ├── chunks
│ │ └── 000001
│ ├── index
│ ├── meta.json
│ └── tombstones
├── chunks_head
│ ├── 000106
│ └── 000107
├── lock
├── queries.active
└── wal
├── 00000104
├── 00000105
├── 00000106
├── 00000107
└── checkpoint.00000103
└── 00000000
meta.json 文件内容长这样,可以看出这个 Block 是由 3个 Block合并而来
/prometheus/storage_v2/01GHQEVZ468HWPJ9QMD065FP61 # cat meta.json
{
"ulid": "01GHQEVZ468HWPJ9QMD065FP61",
"minTime": 1668276000000,
"maxTime": 1668297600000,
"stats": {
"numSamples": 27940320,
"numSeries": 19403,
"numChunks": 232836
},
"compaction": {
"level": 2,
"sources": [
"01GHPT8R6VZVXMAX84BBAYNH1M",
"01GHQ14FET0WY8Z44TFYY569QR",
"01GHQ806PVY5AATJ4K4209HJFB"
],
"parents": [
{
"ulid": "01GHPT8R6VZVXMAX84BBAYNH1M",
"minTime": 1668276000000,
"maxTime": 1668283200000
},
{
"ulid": "01GHQ14FET0WY8Z44TFYY569QR",
"minTime": 1668283200000,
"maxTime": 1668290400000
},
{
"ulid": "01GHQ806PVY5AATJ4K4209HJFB",
"minTime": 1668290400000,
"maxTime": 1668297600000
}
]
},
"version": 1
}/prometheus/storage_v2/01GHQEVZ468HWPJ9QMD065FP61 #
(完)
References: