1. 什么是 compaction ?
Compaction 顾名思义,就是对 SSTable 文件进行合并,分为两种:
- Minor Compaction: 把
MemDB写入到文件系统,生成SSTable - Major Compaction: 把
Level N层的一个或多个SSTable与Level N+1层的一个或多个SSTable进行合并,把合并结果写入到Level N+1层的一个或多个文件中。
2. 为什么要进行 compaction ?
2.1 数据持久化
为了提升写入速率,LevelDB 是先把数据写到内存的 MemDB,为了数据持久化,Minor Compaction 会把MemDB作为一个整体,写入 SSTable 文件,这些文件都存放在 Level 0 中。
2.3 提升读取效率
由于用户输入数据的不确定性,Level 0中的 SSTable 是可能会相互重叠的(overlap),如果不做处理的话,查询一个Key时,需要遍历所有的SSTable,这样会导致查询效率很低。因此,需要把Level 0中的数据进行整理,排序之后写入 Level 1,减少查询时需要读取的SSTable数量。
当 Level 1 的SSTable越来越多之后,每次将 Level 0的文件合并到 Level 1时,需要读取的SSTable 数量、数据量也会越来越大,这样会导致 compaction 越来越慢。因此需要把 Level 1 中的 SSTable 往更高 Level 合并,这样可以减少 Level 1 的数据量。另外,低 Level 的数据是最近写入的,高 Level 的数据是很久之前写入的,根据局部性原理,也可以加快查询速度。
LevelDB 最多有 7 层,Ref: kNumLevels
2.3 整理数据
Compaction 在合并有重叠的 SSTable 时,会把相同 key 的数据进行整理,在频繁修改同一个 key 的场景下,可以减少很多存储空间,也可以加快查询速度,避免读到过期的数据。
3. 什么时候触发 compaction ?
触发 compaction 有三种情况:
- 情况1: 对于 Level 0: 当文件数大于 4 时,触发 compaction
- 情况2:对于 Level N (N > 0): 当该 Level 的数据总大小大于
10 ** N MB时,触发 compaction。也就是,Level 110 MB,Level 2100 MB 以此类推。最后一层没有大小限制。 - 情况3:对某个 SSTable 的查询次数过多,也就是查了很多次(相同或不同的可以),没有一次命中。
前两种情况,会在每次 compaction 结束时,通过积分的形式来表示。
- 情况1: score = level 0 文件数量 / 4
- 情况2:score = level i 数据总大小 / (10 ** i MB)
4. 怎么进行 compaction ?
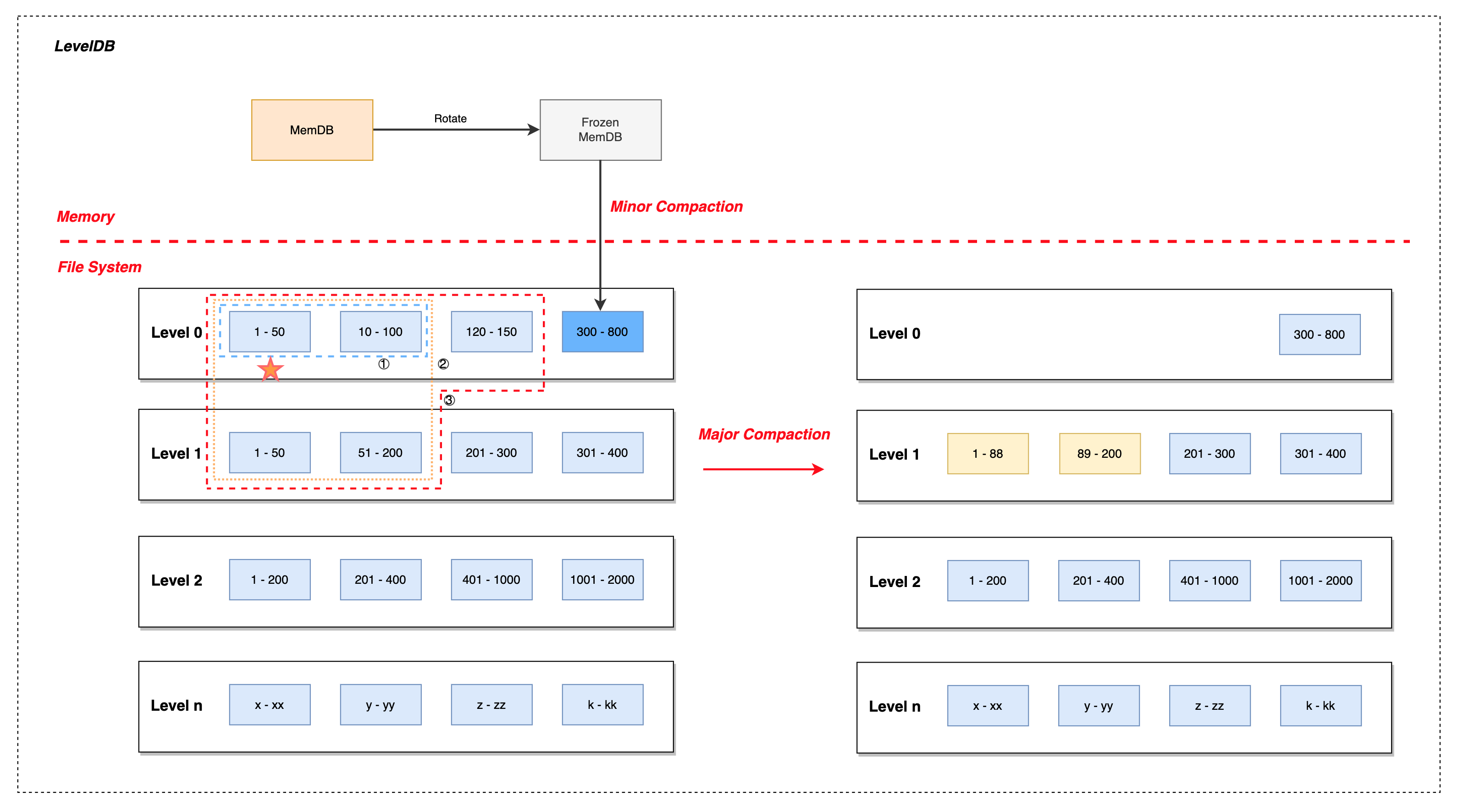
4.1 选择输入的SSTable
对于满足compaction 的 level,会选取部分SSTable来作为初始的输入文件,优先处理情况1、情况2。
- 对于情况1、情况2,当积分大于 1 时,就需要 compaction:
- 对于 Level 0:输入的是第一个 SSTable 文件
- 对于 Level N (N > 0) :会采用轮转法来选择,也就是上一次compaction处理的最后一个 SSTable的下一个文件,通过记录上一次 compaction 处理的
max key来实现。
- 对于情况3:之前已经记录了,直接将其作为输入
4.2 尝试扩大compaction范围
- 记选中的文件在
Level i - 若
i==0(图中五角星),则会在其同一层中,找到与其有overlap的其它SSTable,一同作为输入。(图中蓝色虚线框) - 然后会在
Level i+1找到与其有 overlap 的其它 SSTable(图中橙色虚线框)。 - 最后在不改变
Level i+1输入文件数量(橙色框)的前提下,尝试扩大Level i文件数量(图中红色框)。其实就是拿Level i+1被选中的文件,反向去找Level i中与其overlap的文件。
4.2.1 Trivial compaction
有一种特殊情况,就是与 level i + 1 overlap 的文件数量为0,且与level i + 2 overlap的文件数量小于 10 个,此时可以直接把输入的文件从level i 移动到 level i + 1,而不需要进行归并操作。
4.3 多路归并
对于选中的输入,做多路归并。具体实现起来,就是创建多个迭代器,按序从多个迭代器中取出数据,写入新文件,放到Level i+1层中。由于单个SSTable有大小限制,默认2MB。因此在合并过程中,可能会产生多个新的 SSTable(图中黄色部分)。
怎么处理更新数据或者是删除数据呢?其实遍历的时候都是按从大到小的seq顺序来遍历key的:
- 对于删除:
- 如果更高层没有相同的 key 了,则直接删了
- 如果有,则还需要写入 del key 到 SSTable 中,等 compact 到更高层后,再从 SSTable文件中删除
- 对于更新:
- 直接写入新值,旧值略过
新的SSTable 写完之后,需要删除作为输入的那些SSTable,当然不是立即删除,由于Snapshot的存在,只是把这些文件的引用计数减1,待引用为0后,再进行删除。
(完)
References: