遇到一个有趣的C语言习题,题目很好地考察了数据在内存中的存储方式以及函数调用时的stack管理。题目如下:

题目大意为:给定一个加密后的字节数组,以及一个解密程序,解密程序需要四个key才能成功解密。我们可以先找出前两个key,这时会得到一个以“From:”开头的伪消息。利用这两个key,接着寻找key3,key4使extract_message2得以运行,从而输出最终结果。
解密程序如下:
#include <stdio.h>
#include <stdlib.h>
int data [] = {
0x63636363, 0x63636363, 0x72464663, 0x6F6D6F72,
0x466D203A, 0x65693A72, 0x43646E20, 0x6F54540A,
0x5920453A, 0x54756F0A, 0x6F6F470A, 0x21643A6F,
0x594E2020, 0x206F776F, 0x79727574, 0x4563200A,
0x6F786F68, 0x6E696373, 0x6C206765, 0x796C656B,
0x2C336573, 0x7420346E, 0x20216F74, 0x726F5966,
0x7565636F, 0x20206120, 0x6C616763, 0x74206C6F,
0x20206F74, 0x74786565, 0x65617276, 0x32727463,
0x6E617920, 0x680A6474, 0x6F697661, 0x20646E69,
0x21687467, 0x63002065, 0x6C6C7861, 0x78742078,
0x6578206F, 0x72747878, 0x78636178, 0x00783174
};
char message[100];
void usage_and_exit(char * program_name) {
fprintf(stderr, "USAGE: %s key1 key2 key3 key4\n", program_name);
exit(1);
}
void process_keys12 (int * key1, int * key2) {
*((int *) (key1 + *key1)) = *key2;
}
void process_keys34 (int * key3, int * key4) {
*(((int *)&key3) + *key3) += *key4;
}
char * extract_message1(int start, int stride) {
int i, j, k;
int done = 0;
for (i = 0, j = start + 1; ! done; j++) {
for (k = 1; k < stride; k++, j++, i++) {
if (*(((char *) data) + j) == '\0') {
done = 1;
break;
}
message[i] = *(((char *) data) + j);
}
}
message[i] = '\0';
return message;
}
char * extract_message2(int start, int stride) {
int i, j;
for (i = 0, j = start;
*(((char *) data) + j) != '\0';
i++, j += stride)
{
message[i] = *(((char *) data) + j);
}
message[i] = '\0';
return message;
}
int main (int argc, char *argv[])
{
int dummy = 1;
int start, stride;
int key1, key2, key3, key4;
char * msg1, * msg2;
key3 = key4 = 0;
if (argc < 3) {
usage_and_exit(argv[0]);
}
key1 = strtol(argv[1], NULL, 0);
key2 = strtol(argv[2], NULL, 0);
if (argc > 3) key3 = strtol(argv[3], NULL, 0);
if (argc > 4) key4 = strtol(argv[4], NULL, 0);
process_keys12(&key1, &key2);
start = (int)(*(((char *) &dummy)));
stride = (int)(*(((char *) &dummy) + 1));
if (key3 != 0 && key4 != 0) {
process_keys34(&key3, &key4);
}
msg1 = extract_message1(start, stride);
if (*msg1 == '\0') {
process_keys34(&key3, &key4);
msg2 = extract_message2(start, stride);
printf("%s\n", msg2);
}
else {
printf("%s\n", msg1);
}
return 0;
}
运行平台
- OS: Ubuntu 15.10 64-bit
- IDE: Eclipse Mars with CDT
- Compiler: GCC 5.2.1 20151010
Key1
刚开始不知从何下手,两个处理key的程序只知道是移动指针并更改其对应的内存,而两个输出程序中循环又看不太懂。于是注意力回到主函数中。
可以看到,输出程序中用到的start与stride是根据dummy来控制循环的。而主函数中只是定义了dummy=1,之后并没有对其做出改变。可想而知,计算start及stride时dummy不可能为1。而在这之前只有process_key12可能改变dummy的值。由此可以推断,在process_key12中,通过移动key3,使其指向dummy,从而得以改变其值。
在Eclipse的debug模式下,进入process_key12之前,观察到&dummy=0x7fffffffd9bc;进入process_key12之后,观察到key1=0x7fffffffd9c0。故key3需要向低地址方向移动4个字节。
由*((int *) (key1 + *key1)) = *key2;可知,会将(key1 + *key1)转换为int*,故*key1应为-1。
(此处key1的值为main函数中key1的地址。)
Key2
dummy剖析
那么dummy的值应该设为多少呢?也即key2的值应为多少呢?我们先来看看start与stride是怎么利用dummy的。
start = (int)(*(((char *) &dummy)))表示start为dummy的末两个字节
stride = (int)(*(((char *) &dummy) + 1))表示stride为dummy的低3、4个字节。
为什么这么说呢?因为数据在本实验机器上是按little-endian方式存储的。低位放在低地址处。比如0x0A0B0C0D中,0D是低位,故其应该放在低地址处。
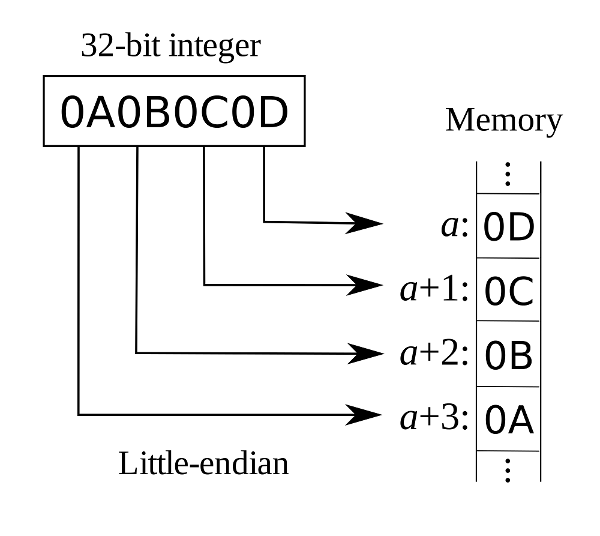
注意,通常我们所说的变量的地址,值得是其整个存储单元的最低地址。示例中0D的地址即为该变量的地址。示例中的0x0D相当于start,0x0C相当于stride。整个变量相当于dummy。
由此可见,我们只需要利用key2低4个字节的数据,而其高四个字节的数据并没有用到。key2由键盘读入,并且先通过strtol函数转换为long类型的变量,接着取其低四个字节的数据存于key2变量之中。由于实验机器是64位字长,因此long类型为8个字节,故传入的第二个数据可以是64位,如0x7FABCDEF12345678,最后0x78对应start,0x56对应stride。
确定start及stride
知道start以及stride怎么来的,接下来就得确定他们的值了。题目说道,当key1,key2正确之后,会输出以From:开头的信息。那么我们就得找找这个开头的F在哪里。
在调试模式下的memory面板中,以ASCII模式看看data中的数据到底是啥。
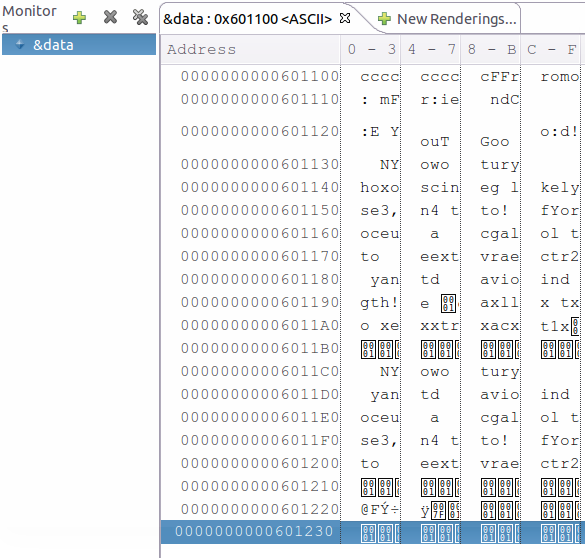
可以看到,字符F在0x601109以及0x60110a处出现,之后还有一处。考虑到还要有m,故打印出来的F只可能在其中选一个。看看From:中的各个字符在data中的排列顺序,这时候我们已经可以猜测,输出程序是跳着输出的,这个肯定跟stride有关。
我们再来看看extract_message1中到底干了什么。遇到\0时跳出所有循环很容易就能看出来,可是为什么要有两个循环呢?内部的循环是执行stride-1次,然后跳出,接着j++,然后又进入内部循环。
i没有什么异样,是用来把数据存到message的索引,与赋值是同步的。k是个用来计数的变量,也没什么问题。对于j呢?j是用来索引data中的数据。从start+1索引处开始,然后在外部和内部的每次循环中都会递增。问题出在内部循环中,j向前移动stride-1,然后再递增,此时,内部循环的条件不满足,开始执行外部循环。于是j又递增,然后再进入内部循环。
由此可见,在extract_message1中,从data[start+1]开始,向前输出stride-1个字符,然后跳过一个,接着又输出stride-1个,然后再跳过一个。。。。按照此规律,直到遇到\0便跳出所有循环。
那么,根据此规律观察上图可以发现,若为第一个F,则输出一个跳一个,但在0x60110F处的o出现异常,本应该是m。故,应从第二个开始,每次输出两个再跳过一个。此时,start为9,stride为3。执行结果为
From: Friend
To: You
Good! Now try choosing keys3,4 to force a call to extract2 and
avoid the call to extract1
因此,输入的第二个参数为0x7FABCDEF12340309(最高位最大为7,低四位为0309,其余任意)或者-0x7FABCDEF1234FCF7(不看负号,最高位最大为7,低四位为FCF7,其余任意)。注意,最高为最大为7,因为strtol返回的结果为signed long,不然就溢出了。上溢之后就按LONG_MAX取值了,也就是0x7fffffffffffffff,那还玩个毛啊。下溢按LONG_MIN取值,即为-LONG_MAX-1
The man of strtol says that:
RETURN VALUE
The strtol() function returns the result of the conversion, unless the
value would underflow or overflow. If an underflow occurs, strtol()
returns LONG_MIN. If an overflow occurs, strtol() returns LONG_MAX.
In both cases, errno is set to ERANGE. Precisely the same holds for
strtoll() (with LLONG_MIN and LLONG_MAX instead of LONG_MIN and
LONG_MAX).
Key3
按照题目的要求,当前两个参数解决之后,需要设法使程序执行extract_message2。但是msg1非空,按照常理并不会执行extract_message2。想要改变现状,也只能在process_key34中做手脚了。观察process_key34,发现他也是个移动指针更改值的东东。只不过这次不是移动主函数中变量的指针了,而是移动process_key34函数中key3的指针。
错误尝试
先来看看process_key34函数中key3的地址吧。&kay3=0x7fffffffd988。在看看与msg1有关的。&message=0x601240,&start=0x7fffffffd9d0,&stride=0x7fffffffd9d4。message不在栈里面,不可能通过相对寻址来改变。那么只能改变start或者stride的值了。
那么要使msg1='\0'以执行extract_message2要怎么控制start,stride的值呢?循环只可能通过遇到\0而终止,而又需要msg1='\0',就只能让循环一开始就遇到\0了。
因此,我们需要改变start的值,使data[stride+1]=0。便在data中寻找00,发现有两处合适。试着通过key3的值把start分别改到那两处,发现结果并不如任意。
修改返回地址
冥思苦想过后,突然发现题目曾提示函数调用时的堆栈管理,这才发现还有一处能使extract_message2得到执行,那便是直接跳过对msg1=='\0'的判断。我们可以通过修改process_key34函数的返回地址,使之执行完后直接返回到msg2 = extract_message2(start, stride);代码处。
那么该怎么更改呢?(明日再续)
说好的明日再续呢?这都过了三四天了!!!
先来看看函数调用时会发生什么
栈帧结构
函数调用时,会有固定格式的栈帧分配,每个被调用的函数都有其返回地址。也就是函数执行完之后返回到代码区下一条指令的地址。
下面是栈帧的结构:
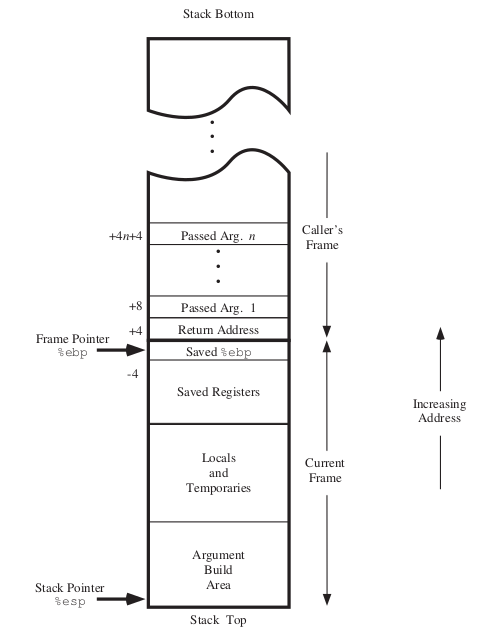
函数调用时,会在内存堆栈中开辟一块临时空间,这块空间称之为stack frame(栈帧)。使用基指针(ebp)与栈指针(esp)来确定栈帧的大小。ebp表示当前帧的最底部,ebp表示堆栈的顶部也就是当前帧的顶部。
当发生函数调用时,首先将需要传递的参数依次push到栈中,然后将执行函数调用之后的下一条指令的地址(在代码区)push到栈中,也就是函数的返回地址。此时,开始进入callee的栈帧。接着,将caller的esp push到栈中,然后便是一些在callee中需要使用到的寄存器的拷贝以及函数中声明的临时变量了。
之所以要保存caller的ebp到callee的栈帧中,是因为当对callee的调用结束时,需要将ebp重新指向caller的底部,以便于弹出caller时计算空间。
在x86-64架构下,传递的参数可以直接存到寄存器中,可以参考此文章X86-64寄存器和栈帧
下面是一个例子:
内存分配
接下来看看本程序的内存分配
当进入主函数时。各变量地址由高到低排列情况如下
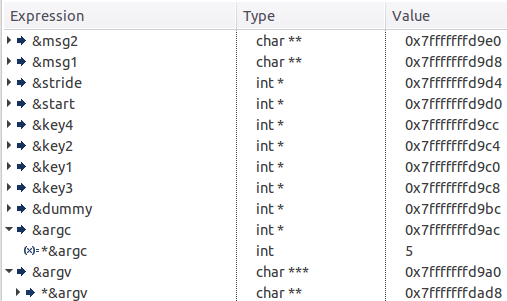
此时,rbp(frame pointer),rsp(stack pointer)的值为

进入process_key12后,寄存器变为

0x7fffffffd998为process_key12的返回地址,其值为0x400948
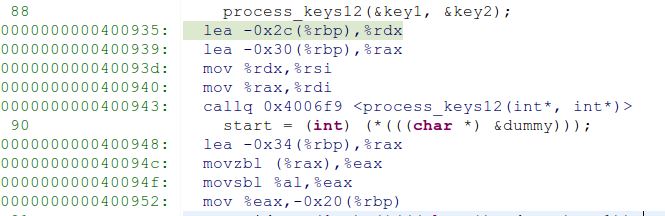
key1,key2地址为。

可以发现,传递给process_key12的参数并没有压入栈中,而是放入了寄存器。因为当前rbp与之前的rsp之间的差值只能存两个地址值,也即返回地址与保存的rbp。但是放入寄存器之后怎么key1还能寻址到呢?而且rsp的值居然比key1的地址大。栈顶下面还会放东西?改天研究研究汇编,看看到底是啥情况。
回到主函数后,rsp,rbp返回原值。接着进入process_key34。由于两个process的函数结构差不多,rsp与rbp的值又同时变为了d990。而key3,key4的地址又到了栈顶之下。。。。

同样,该函数的返回地址为0x7fffffffd998的值,为0x400987
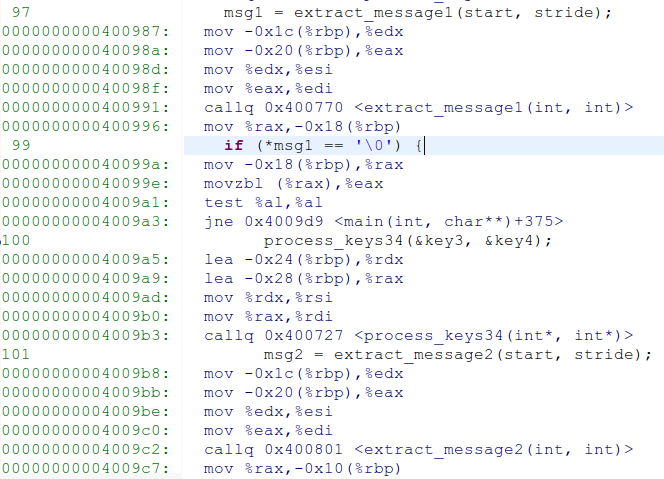
解决方法
有了上面的分析过程,可以发现,我们只需要通过移动process_key34中key3的指针,使其移动到0x7fffffffd998即其返回地址处,然后将返回地址改到0x4009b8处,跳过判断,直接执行msg2 = extract_message2(start, stride)即可。
由于key3地址为0x7fffffffd988,返回地址的指针为0x7fffffffd998。返回地址为0x400987,需要移动到的地址为0x4009b8。故,传入的第三个参数为16/4=4,第四个参数为0xb8-0x87=0x31
由于是在x86-64模式下运行的,与很多同学在VS中win32模式下的结果很不同。除了stride的值在不同平台需要相同外,其余三个参数都是依系统平台与运行模式而定的。而且,好多人好像并没有发现第二个参数的值可以有N多个,因为只是截取了后面两个字节。