1. 学习环境
-
操作系统 Ubuntu Kylin 15.04
-
辅助软件 Eclipse Mars Release (4.5.0)
2. 安装JavaCC
2.1 在Eclipse中安装JavaCC插件
2.1.1 下载JavaCC插件
打开Eclipse后,在菜单栏依次选择"Help->Eclipse Marketplace"。在弹出窗口的"Search"面板中,键入"JavaCC"进行搜索,搜索结果显示之后选择"Install"进行安装即可。
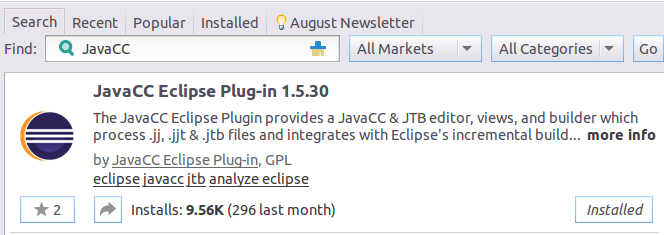
2.1.2 试用JavaCC插件
新建一个Java项目,以及一个Java package,然后建立一个JavaCC Template File。JavaCC Console 报出如下错误:

原因是JavaCC插件配置中,javacc-5.0.jar的路径配置错误。
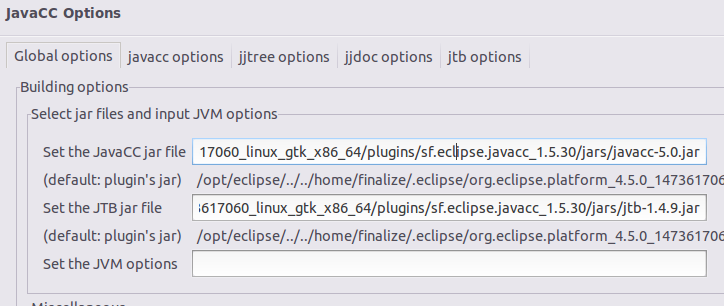
2.1.3 修复JavaCC插件错误配置
在系统文件管理器中,找到了javacc-5.0.jar的实际路径,打开项目配置页,在“JavaCC Options”选项栏中填入实际的Jar文件路径(在jar文件前添加“jars/”即可)。同样适用于JTB jar file的路径。
2.2 安装独立Jar包
2.2.1 下载独立Jar包
在JavaCC官网下载java-6.0.zip。压缩包内包含独立Jar包以及JavaCC文档及示例程序。
2.2.2 将Jar包添加到系统CLASSPATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib/javacc.jar
2.2.3 创建shell script,简化运行命令
创建一个名为javacc的shell脚本文件,输入以下内容
#!/bin/sh
java javacc $*
使用chown root:root javacc 命令,改变文件owner,并将文件添加到/usr/bin目录

2.2.4 键入命令,运行javacc
同理可以使用以上方法创建jjtree、jjdoc的shell脚本
2.2.5 Debian/Ubuntu系统下安装
Debian/Ubuntu系统下,软件源中已存在javacc,使用如下命令即可完成安装
sudo apt-get install javacc
3. JavaCC(Java Compiler Compiler)简介
顾名思义,JavaCC是一个词法分析器和语法分析器的生成工具。其主要功能是通过用户给定的文法规则,生成一个纯Java语言编写的语法分析器。用户输入一段测试字符串,该分析器就能判断该字符串是否满足该文法的规则。检测合法性的同时,也可以生成该字符串的语法分析树。另外,该工具还能根据用户定义的模板文件生成对应的描述该语言的文档。
通常所说的javacc指的是javacc.jar这个jar包,jar包中包含三个主要可执行类
- javacc 根据模板文件生成语法分析器
- jjtree 根据模板文件生成语法生成树
- jjdoc 根据模板文件生成对应语言的文档
其工作流程如下:
- 输入:一些以正则表达式表示的词法单元,还有一些使用这些词法单元的语法规则
- 输出:一个词法分析器:读取输入并将其拆分为词法单元(Token);一个语法分析器,分析输入的字符串是否满足定义的语法规则
- JavaCC文件格式为
MyParser.jj jj文件通过命令javacc MyParser.jj进行处理- 处理之后,会生成以下文件:
MyParser.java:生成的语法分析器MyParserTokenManager.java:生成的词法分析器MyParserConstants.java:一些常量
用户编写的模板文件以.jj或.jjt结尾,jj文件由javacc解析并生成java源代码;jjt文件由jjtree解析并生成jj文件。另外,jjdoc通过解析jj文件生成文法的描述文档。示意图如下:
Demo.jjt --> Demo.jj --> Demo.java --> Demo.class --> execute
下面分别学习以上三个模块
4. javacc学习
javacc通过解析.jj的模板文件,生成自上而下的语法分析器。在默认情况下,javacc生成LL(1)语法分析器,用户可以自定义LookAhead的值,使其分析LL(k)语法。
下面先分析jj文件的书写语法,然后通过几个实例来进一步了解javacc
4.1 javacc语法
阅读官方的语法文档可知,jj和jjt文件的语法规则为(以BNF形式表示)
javacc_input ::= javacc_options
"PARSER_BEGIN" "(" <IDENTIFIER> ")"
java_compilation_unit
"PARSER_END" "(" <IDENTIFIER> ")"
( production )*
<EOF>
其中,javacc_options包含一些配置选项,以下列出一些主要的选项
- "LOOKAHEAD" "=" java_integer_literal ";" 设置向前看的值,默认为1,对应于LL(1)文法
- "DEBUG_PARSER" "=" java_boolean_literal ";" 输出语法分析调试信息,默认为false
- "DEBUG_TOKEN_MANAGER" "=" java_boolean_literal ";" 输出词法分析调试信息,默认为false
- "IGNORE_CASE" "=" java_boolean_literal ";" 词法分析忽略大小写,默认为false
- "OUTPUT_DIRECTORY" "=" java_string_literal ";" 生成的java源文件的存放目录,默认为当前工作目录
PARSER_BEGIN与PARSER_END之间的部分为java代码,将会被复制到生成的主程序中,其中IDENTIFIER为生成的主程序类名,因此java_compilation_unit中的类声明应与之相同。
对于production,定义为
production ::= javacode_production
| regular_expr_production
| bnf_production
| token_manager_decls
此处不再展开对相应语法部分的介绍,详情可以参阅官方文档。以下通过几个例子来熟悉javacc语法。
4.2.1 示例1:Java注释解析
java的注释分为单行注释//与多行注释(包含文档注释)/*....*/,其中多行注释不允许嵌套,即形如/*aaa/*bbb*/ccc*/的形式是不合法的。下面将编写jj文件,描述其文法规则,并生成分析程序。
options { static = true; }
PARSER_BEGIN(Comments)
public class Comments {
public static void main(String args []) throws ParseException {
Comments parser = new Comments(System.in);
while (true){
System.out.print("Please input a java comment ended with \";\":");
try {
Comments.readline();
System.out.println("OK.");
}
catch (Exception e) {
System.out.println("NOK.");
System.out.println(e.getMessage());
Comments.ReInit(System.in);
}
}
}
}
PARSER_END(Comments)
SKIP :
{
" " | "\r" | "\t" | "\n"
| "/*" : WithinComment
| <"//" (~["\n","\r"])* ("\n"|"\r"|"\r\n")>
}
TOKEN: { <SEMICOLON:","> }
< WithinComment >
SKIP : { "*/" : DEFAULT }
< WithinComment >
MORE :{ < ~[ ] > }
void readline() :{}{ <SEMICOLON> }
以上程序中,OPTION中的static表示文件中声明的java函数以及类变量在生成的源代码中都会被声明为static。PARSER_BEGIN与PARSER_END中的代码将会被复制到生成的主程序中(Comments.Java)中。
SKIP中定义的内容表示词法分析器会忽略其中的内容,不会尝试将其与TOKEN中定义的词法单元进行匹配。MORE表示不会忽略也不会立即进行匹配,而是将其暂存到缓冲区中,等到下一个TOKEN或SPECIAL TOKEN出现时在一起进行匹配。
我们可以定义多个lexical states(词法状态),并在多个词法状态之间进行切换。例子中WithinComment就表示为一个词法状态,未命名的词法状态都默认属于状态DEFAULT。当遇到"/*"时,词法状态转换到WithinComment,MORE中的~[]表示匹配所有字符。当遇到*/时,词法状态又条回到DEFAULT,完成了对多行注释的解析。
分析器从readline函数开始,词法分析器会读取用户输入的字符串,语法分析器拿到此法分析的Token后依次与readline中定义的语法进行匹配,直至匹配完成或出现错误。本例中,只需匹配到<SEMICOLON>即标志着成功解析。在这之前的注释都会被忽略。
void readline() :{}{ <SEMICOLON> }中第一处{}表示java代码块,我们可以在其中声明一些变量或进行输出等。第二处{}中的内容以BNF方式表示,标志着语法规则。由于本例过于简单,故采用下面的例子进行说明。
示例中,OPTION、MORE等关键字所遵循的语法规则为,具体参见官方文档
regular_expr_production ::= [ lexical_state_list ]
regexpr_kind [ "[" "IGNORE_CASE" "]" ] ":"
"{" regexpr_spec ( "|" regexpr_spec )* "}"
readline()遵循的语法规则为,具体参见官方文档
bnf_production ::= java_access_modifier java_return_type java_identifier "(" java_parameter_list ")" ":"
java_block
"{" expansion_choices "}"
4.2.2 示例2:C语言指针表达式解析
C语言中,当指针与数组、函数等表达式结合在一起时会显得尤为复杂。如char (*(*x[3])())[5];就很难一眼看出其含义。因此,可以提取其文法规则,利用javacc生成其解析程序。
参考《The C Programming Language》以及C Right-Left Rule。其语法为
dcl:
optional *'s direct-dcl
direct-dcl:
id
(dcl)
direct-dcl()
direct-dcl[optional size]
消除左递归及合并左公因子后,得到
dcl -> ("*")* dirdcl
dirdcl -> ( id | "("dcl")" ) ddcl
ddcl -> ( "()" | "[" [num] "]" ) ddcl | ε
因此可以得到如下jj文件
public class PGrammer
{
private static Token identifier;
private static Token type;
private static StringBuilder out = new StringBuilder();
public static void main(String args []) throws ParseException
{
PGrammer parser = new PGrammer(System.in);
while (true)
{
System.out.println("Enter a C pointer expression like \"int (*a)();\" or \";\" to quit:");
try
{
if (PGrammer.expr() == 1) break;
}
catch (Exception e)
{
System.out.println("NOK.");
System.out.println(e.getMessage());
PGrammer.ReInit(System.in);
}
catch (Error e)
{
System.out.println("Oops.");
System.out.println(e.getMessage());
break;
}
System.out.format("%s: %s %s\n", identifier.image, out.toString(), type.image);
out.setLength(0);
}
}
}
PARSER_END(PGrammer)
SKIP :
{
" " | "\r" | "\t" | "\n"
}
TOKEN : /* OPERATORS */
{
< POINTER : "*" >
| < LPARENTH : "(" > | < RPARENTH : ")" >
| < LBRACKET : "[" > | < RBRACKET : "]" >
}
TOKEN :
{
< #LETTER : [ "a"-"z", "A"-"Z" ] >
| < #DIGIT : [ "0"-"9" ] >
| < NUMBER : [ "1"-"9" ] (< DIGIT >)* >
| < TYPE : "char" | "int" | "float" | "double" >
| < IDENTIFIER : < LETTER >( < DIGIT > | < LETTER > | "_" )* >
}
int expr() :
{}
{
type = < TYPE > dcl() ";" { return 0; }
| ";" { return 1; }
}
void dcl() :
{
int pcount = 0;
}
{
(< POINTER > { pcount++;})* dirdcl()
{
for (int i = 0; i < pcount; i++)
{
out.append("pointer to");
}
}
}
void dirdcl() :
{}
{
( identifier = < IDENTIFIER >
| < LPARENTH > dcl() < RPARENTH >
)ddcl()
}
void ddcl() :
{
Token arr = null;
}
{
[
(
< LPARENTH > < RPARENTH >
{
out.append(" function returning ");
}
| < LBRACKET > [ arr = < NUMBER > ] < RBRACKET >
{
if (arr != null) out.append(" array [" + arr.image + "] of ");
else out.append(" array [] of");
}
)ddcl()
]
}
上面的例子中,TOKEN中的字面值常量表示文法中的终结符,尾部定义的函数表示文法中的非终结符。可以发现,在非终结符的文法表示中,用{}插入了java代码,本例中插入的java代码大多为输出语句。对于插入的代码,当语法分析器解析完其之前的文法符号后,会执行该代码段中的代码。
在主程序中,定义了两个Token静态成员以及一个StringBuilder静态成员用以记录需要输出的内容。由于要在接下来的非终结符解析函数中使用到这些成员,而解析函数默认为静态,故声明为静态。
对于每一个Token对象,都有image属性表示其对应的字符串,当我们需要使用时,可以在解析函数中定义一个Token变量用以获取Token。如ddcl()中定义的arr,它用来记录数组表达式中的索引值。使用arr=<NUMBER>即可获取词法分析器解析的TOKEN,然后通过arr.image获取其字符串形式。
现在,我们可以解析上面那个复杂的指针表达式了,解析结果为
$ java PGrammer
Enter a C pointer expression like "int (*a)();" or ";" to quit:
char (*(*x[3])())[5];
x: array [3] of pointer to function returning pointer to array [5] of char
如果在options中添加DEBUG_PARSER=true或DEBUG_TOKEN_MANAGER=true可以分别查看其语法分析过程和词法分析过程。
4.3 jjtree学习
jjtree是javacc的预处理器,它通过处理JavaCC源文件,在其中加入语法分析树的生成程序,使得最后生成的语法分析器能够生成所输入字符串的语法分析树。
jjtree的处理模式包含简单和复杂两种,简单模式下,jjtree,默认为所有的非终结符生成一个树节点Node,用户可以自定义对某些非终结符不生成节点。复杂模式下,用户需要实现Node接口,提供一个自定义的Node类。这里我们只使用简单模式。
因为JavaCC是一个自上而下的语法分析器,jjtree则自下而上生成语法分析树。处理程序会维护一个Node栈,将非终结符对应的Node依次push到栈中。当找到其父节点时,会将子节点pop出栈,并将其附加到父节点上,同时将父节点push到栈中。按照此规则,直到解析完成为止。最后,栈中将只会存在根节点,程序会依次打印附在根节点上所有子节点的信息,由此完成语法分析树的构建。
我们在jj文件适当的地方加入一些处理动作,保存为jjt文件,即可完成语法分析树程序的源文件。默认情况下,会生成与非终结符同名的节点,我们可以在函数名后面加入自定义的名称,如上例中的expr:
int expr()#expression :
{}
{
type = < TYPE > dcl() ";" { return 0; }
| ";" { return 1; }
}
如果对某终结符,不想生成对应的节点,则可以在其后加入#void.如上例中的ddcl:
void ddcl()#void :
{
Token arr = null;
}{......}
上面#expression是一种简写方式,等价于#expression(true)。因为JJTree提供了两种节点的定义方式:
- 确定性的节点,也就是能确定其子节点的个数,表示形式为
#Nodename(INTEGER EXPRESSION)。最多只有那么多节点可以弹出Node栈,并附加到它上面作为其子节点。 - 条件节点,也就是满足条件的子节点可以附加到其上,表示形式为
#Nodename(CONDITION)。
一般默认使用#node(true)也即#node的表示方式
4.3.1 使用JJTree处理示例2
我们可以对上述示例2进行简单的处理,让其能构建语法分析树。
对于readline,它将返回一个SimpleNode对象,以便于最后对语法树的输出。同时也给它对应的节点重命名为expr。
SimpleNode readline()#expr :
{}
{
type = < TYPE > dcl() ";"
{ return jjtThis; }
| ";" { return null; }
}
其中,jjtThis是当前Node的引用。对主函数做如下更改:
try
{
if ((node=PGrammer.readline()) !=null)
node.dump(">>");
else
break;
}
其中,dump表示将node作为语法树的根节点,输出其所有子节点的信息。参数">>"表示输出时的前缀。我们只对示例2中的程序作出以上更改,其他非终结符按默认形式生成树节点。将文件保存为.jjt文件,最终得到结果:
$ java PGrammer
Enter a C pointer expression like "int (*a)();" or ";" to quit:
char (*(*x[3])())[5];
>>expr
>> dcl
>> dirdcl
>> dcl
>> dirdcl
>> dcl
>> dirdcl
>> ddcl
>> ddcl
>> ddcl
>> ddcl
>> ddcl
>> ddcl
x: array [3] of pointer to function returning pointer to array [5] of char
4.4 jjdoc学习
jjdoc通过读取JavaCC源文件,生成其对应的语法描述文档。有以下参数可供选择
- TEXT(默认为false),默认生成HTML文件,TEXT设为true则生成文本文件
- BNF(默认为false),设为true则生成纯BNF文档
- ONE_TABLE(默认为true),设为false则每个产生式生成一个表格
- OUTPUT_FILE,输出文件目录
- CSS,为生成的HTML文档指定样式表
下面对示例2中的jj文件生成文档:
jjdoc -ONE_TABLE=false PointerExp.jj
结果如下


5. CMM语法解析程序
对于CMM语言的词法语法分析程序,我们只需要首先归纳出其文法规则,然后将其文法规则转换为对应的JavaCC模板文件即可。
CMM语言的文法规则如下:
NEWLINE ::= "\r"? "\n"
WS ::= " "|"\t"
IF ::= "if"
ELSE ::= "else"
WHILE ::= "while"
READ ::= "read"
WRITE ::= "write"
INT ::= "int"
REAL ::= "real"
BOOL ::= "bool"
TRUE ::= "true"
FALSE ::= "false"
PLUS ::= "+"
MINUS ::= "-"
TIMES ::= "*"
DIVIDE ::= "/"
ASSIGN ::= "="
LT ::= "<"
GT ::= ">"
EQUAL ::= "=="
NEQUAL ::= "<>"
LPAREN ::= "("
RPAREN ::= ")"
LBRACE ::= "{"
RBRACE ::= "}"
LBRACKET ::= "["
RBRACKET ::= "]"
ROWCOMM ::= "//"
LEFTCOMM ::= "/*"
RIGHTCOMM ::= "*/"
COMMA ::= ","
SEMICOLON ::= ";"
LETTER ::= ["a"-"z"]|["A"-"Z"]
DIGIT ::= ["0"-"9"]
ID ::= <LETTER> ( ( <LETTER> | <DIGIT> | "_" ) * ( <LETTER> | <DIGIT> ) )?
INT_LITERAL ::= ["1"-"9"] (<DIGIT>)* | "0"
REAL_LITERAL::= <INT_LITERAL> ( "."( <INT_LITERAL> )+ )?
program ::= statement
statement ::= ( ifStmt | whileStmt | readStmt | writeStmt | assignStmt | declareStmt )+
ifStmt ::= <IF> <LPAREN> condition <RPAREN> <LBRACE> statement <RBRACE> ( <ELSE> <LBRACE> statement <RBRACE> )?
whileStmt ::= <WHILE> <LPAREN> condition <RPAREN> <LBRACE> statement <RBRACE>
readStmt ::= <READ> <LPAREN> <ID> <RPAREN> <SEMICOLON>
writeStmt ::= <WRITE> <LPAREN> expression <RPAREN> <SEMICOLON>
assignStmt ::= <ID> [array] <ASSIGN> expression <SEMICOLON>
declareStmt ::= (<INT> | <REAL> | <BOOL>) [array] <ID> ( <COMMA> <ID>)* <SEMICOLON>
condition ::= (expression compOp expression)|<TRUE>|<FALSE>
expression ::= term (addOp term)*
term ::= factor (mulOp factor)*
compOp ::= <LT> | <GT> | <EQUAL> | <NEQUAL>
addOp ::= <PLUS> | <MINUS>
mulOp ::= <TIMES> | <DIVIDE>
factor ::= <REAL_LITERAL> | <INT_LITERAL> | <ID> | <LPAREN> expression <RPAREN> | <ID> array
array ::= <LBRACKET> ( <INT_LITERAL> | <ID> ) <RBRACKET>
将其转换为JavaCC模板文件时,只需要将终结符号转换为TOKEN中的正则表达式,将非终结符转换为函数。此外,对于单行和多行注释,按照示例1的做法即可。
对于主函数,采用文件读入或键盘读入源代码这两种方式。文件路径以命令行参数的形式传入,键盘读入以EOF结束。成功解析或解析失败都会结束程序。
以上就是JavaCC的学习内容。CMM词法语法解析的模板文件为同目录下CMMGrammer.jj,java源代码在src/目录, 生成的可执行程序在/bin目录。测试文件在tests/目录。
执行方法:
$cd bin
java cmm.CMMGrammer # read source code from keyboard
java cmm.CMMGrammer file # read source code from file